Attention, Perception, & Psychophysics ( IF 1.7 ) Pub Date : 2022-04-26 , DOI: 10.3758/s13414-022-02478-3 Xinger Yu 1, 2 , Joy J. Geng 1, 2 , Simran K. Johal 2
|
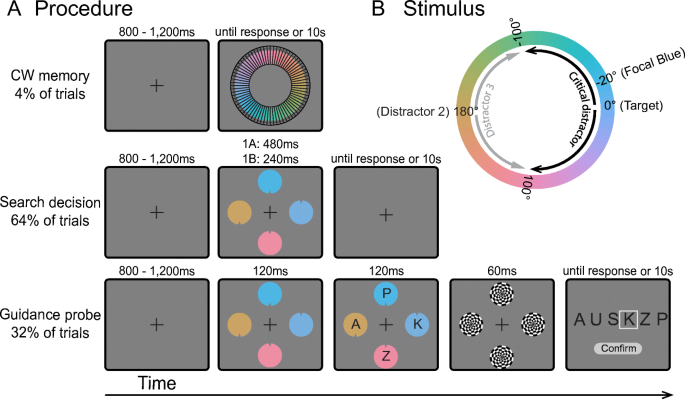
When searching for an object, we use a target template in memory that contains task-relevant information to guide visual attention to potential targets and to determine the identity of attended objects. These processes in visual search have typically been assumed to rely on a common source of template information. However, our recent work (Yu et al., 2022) argued that attentional guidance and target-match decisions rely on different information during search, with guidance using a “fuzzier” version of the template compared with target decisions. However, that work was based on the special case of search for a target amongst linearly separable distractors (e.g., search for an orange target amongst yellower distractors). Real-world search targets, however, are infrequently linearly separable from distractors, and it remains unclear whether the differences between the precision of template information used for guidance compared with target decisions also applies under more typical conditions. In four experiments, we tested this question by varying distractor similarity during visual search and measuring the likelihood of attentional guidance to distractors and target misidentifications. We found that early attentional guidance is indeed less precise than that of subsequent match decisions under varying exposure durations and distractor set sizes. These results suggest that attentional guidance operates on a coarser code than decisions, perhaps because guidance is constrained by lower acuity in peripheral vision or the need to rapidly explore a wide region of space while decisions about selected objects are more precise to optimize decision accuracy.
中文翻译:
视觉搜索指导使用比目标匹配决策更粗略的模板信息
在搜索对象时,我们使用内存中包含任务相关信息的目标模板来引导视觉注意潜在目标并确定参与对象的身份。视觉搜索中的这些过程通常被认为依赖于模板信息的公共来源。然而,我们最近的工作 (Yu et al., 2022) 认为,注意力引导和目标匹配决策在搜索过程中依赖于不同的信息,与目标决策相比,使用模板的“模糊”版本进行引导。然而,这项工作是基于在线性可分离干扰物中搜索目标的特殊情况(例如,在黄色干扰物中搜索橙色目标)。然而,现实世界的搜索目标很少与干扰项线性分离,并且尚不清楚用于指导的模板信息的精度与目标决策之间的差异是否也适用于更典型的条件。在四个实验中,我们通过在视觉搜索过程中改变干扰物的相似性和测量注意力引导对干扰物和目标错误识别的可能性来测试这个问题。我们发现,在不同的曝光持续时间和干扰集大小下,早期注意力引导确实不如随后的匹配决策精确。这些结果表明,注意力引导的代码比决策更粗略,这可能是因为引导受到周边视觉敏锐度较低或需要快速探索广阔空间区域的限制,而关于选定对象的决策更精确以优化决策准确性。










































 京公网安备 11010802027423号
京公网安备 11010802027423号