当前位置:
X-MOL 学术
›
Phys. Chem. Chem. Phys.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Data undersampling models for the efficient rule-based retrosynthetic planning
Physical Chemistry Chemical Physics ( IF 2.9 ) Pub Date : 2021-11-08 , DOI: 10.1039/d1cp03630k Min Sik Park 1 , Dongseon Lee 1 , Youngchun Kwon 1, 2 , Eunji Kim 1, 3 , Youn-Suk Choi 1
Physical Chemistry Chemical Physics ( IF 2.9 ) Pub Date : 2021-11-08 , DOI: 10.1039/d1cp03630k Min Sik Park 1 , Dongseon Lee 1 , Youngchun Kwon 1, 2 , Eunji Kim 1, 3 , Youn-Suk Choi 1
Affiliation
|
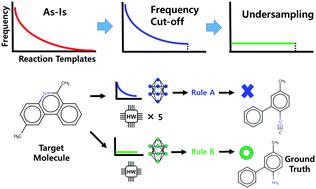
Computer-aided retrosynthetic planning for organic molecules, which is based on a large synthetic database, is a significant part of the recent development of autonomous robotic chemists. As in other AI fields, however, the class imbalance problem in the dataset affects the prediction performance of retrosynthetic paths. Here, we demonstrate that applying undersampling models to the imbalanced reaction dataset can improve the prediction of retrosynthetic templates for target molecules. We report improvements in the top-1 and top-10 prediction accuracies by 13.8% (13.1, 5.4%) and 8.8% (6.9, 2.4%) for undersampling based on the similarity (random, dissimilarity) clustering of molecular structures of products, respectively. These results demonstrate the importance of deep understanding of the statistical distribution, internal structure, and sampling for the training dataset. For practical applications, the target-oriented undersampling model is proposed and confirmed by the improved prediction performance of 9.3 and 4.2% for the top-1 and top-10 accuracies, respectively.
中文翻译:

用于有效的基于规则的逆合成规划的数据欠采样模型
基于大型合成数据库的有机分子的计算机辅助逆合成规划是自主机器人化学家最近发展的重要组成部分。然而,与其他 AI 领域一样,数据集中的类不平衡问题会影响逆合成路径的预测性能。在这里,我们证明将欠采样模型应用于不平衡的反应数据集可以提高对目标分子逆合成模板的预测。我们报告了基于产品分子结构的相似性(随机,相异性)聚类的欠采样,前 1 名和前 10 名预测精度提高了 13.8%(13.1, 5.4%)和 8.8%(6.9, 2.4%),分别。这些结果表明深入了解统计分布、内部结构、并对训练数据集进行采样。在实际应用中,提出了面向目标的欠采样模型,前 1 名和前 10 名的预测性能分别提高了 9.3% 和 4.2%。
更新日期:2021-11-22
中文翻译:
用于有效的基于规则的逆合成规划的数据欠采样模型
基于大型合成数据库的有机分子的计算机辅助逆合成规划是自主机器人化学家最近发展的重要组成部分。然而,与其他 AI 领域一样,数据集中的类不平衡问题会影响逆合成路径的预测性能。在这里,我们证明将欠采样模型应用于不平衡的反应数据集可以提高对目标分子逆合成模板的预测。我们报告了基于产品分子结构的相似性(随机,相异性)聚类的欠采样,前 1 名和前 10 名预测精度提高了 13.8%(13.1, 5.4%)和 8.8%(6.9, 2.4%),分别。这些结果表明深入了解统计分布、内部结构、并对训练数据集进行采样。在实际应用中,提出了面向目标的欠采样模型,前 1 名和前 10 名的预测性能分别提高了 9.3% 和 4.2%。










































 京公网安备 11010802027423号
京公网安备 11010802027423号