Medical Image Analysis ( IF 10.7 ) Pub Date : 2021-11-03 , DOI: 10.1016/j.media.2021.102296 Ziyi Wang 1 , Bo Lu 2 , Xiaojie Gao 3 , Yueming Jin 3 , Zerui Wang 4 , Tak Hong Cheung 5 , Pheng Ann Heng 6 , Qi Dou 6 , Yunhui Liu 1
|
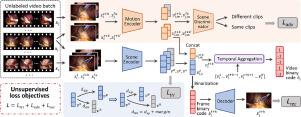
In this paper, we propose a novel method of Unsupervised Disentanglement of Scene and Motion (UDSM) representations for minimally invasive surgery video retrieval within large databases, which has the potential to advance intelligent and efficient surgical teaching systems. To extract more discriminative video representations, two designed encoders with a triplet ranking loss and an adversarial learning mechanism are established to respectively capture the spatial and temporal information for achieving disentangled features from each frame with promising interpretability. In addition, the long-range temporal dependencies are improved in an integrated video level using a temporal aggregation module and then a set of compact binary codes that carries representative features is yielded to realize fast retrieval. The entire framework is trained in an unsupervised scheme, i.e., purely learning from raw surgical videos without using any annotation. We construct two large-scale minimally invasive surgery video datasets based on the public dataset Cholec80 and our in-house dataset of laparoscopic hysterectomy, to establish the learning process and validate the effectiveness of our proposed method qualitatively and quantitatively on the surgical video retrieval task. Extensive experiments show that our approach significantly outperforms the state-of-the-art video retrieval methods on both datasets, revealing a promising future for injecting intelligence in the next generation of surgical teaching systems.
中文翻译:
用于微创手术中视频检索的无监督特征解缠结
在本文中,我们提出了一种用于在大型数据库中检索微创手术视频的无监督场景和运动解缠结 (UDSM) 表示的新方法,该方法具有推进智能和高效手术教学系统的潜力。为了提取更多有区别的视频表示,建立了两个设计的编码器,具有三重排序损失和对抗性学习机制,以分别捕获空间和时间信息,以实现具有良好可解释性的每一帧的分离特征。此外,使用时间聚合模块在集成视频级别上改进了远程时间依赖性,然后产生一组带有代表性特征的紧凑二进制代码,以实现快速检索。整个框架在无监督方案中进行训练,即纯粹从原始手术视频中学习而不使用任何注释。我们基于公共数据集 Cholec80 和我们内部的腹腔镜子宫切除术数据集构建了两个大规模微创手术视频数据集,以建立学习过程并定性和定量地验证我们提出的方法在手术视频检索任务中的有效性。大量实验表明,我们的方法在两个数据集上都显着优于最先进的视频检索方法,揭示了在下一代外科教学系统中注入智能的广阔前景。我们基于公共数据集 Cholec80 和我们内部的腹腔镜子宫切除术数据集构建了两个大规模微创手术视频数据集,以建立学习过程并定性和定量地验证我们提出的方法在手术视频检索任务中的有效性。大量实验表明,我们的方法在两个数据集上都显着优于最先进的视频检索方法,揭示了在下一代外科教学系统中注入智能的广阔前景。我们基于公共数据集 Cholec80 和我们内部的腹腔镜子宫切除术数据集构建了两个大规模微创手术视频数据集,以建立学习过程并定性和定量地验证我们提出的方法在手术视频检索任务中的有效性。大量实验表明,我们的方法在两个数据集上都显着优于最先进的视频检索方法,揭示了在下一代外科教学系统中注入智能的广阔前景。










































 京公网安备 11010802027423号
京公网安备 11010802027423号