当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Benchmarking Machine Learning Models for Polymer Informatics: An Example of Glass Transition Temperature
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2021-10-18 , DOI: 10.1021/acs.jcim.1c01031 Lei Tao 1 , Vikas Varshney 2 , Ying Li 1, 3
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2021-10-18 , DOI: 10.1021/acs.jcim.1c01031 Lei Tao 1 , Vikas Varshney 2 , Ying Li 1, 3
Affiliation
|
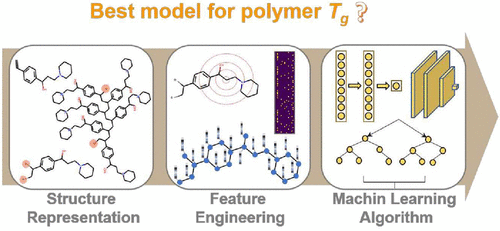
In the field of polymer informatics, utilizing machine learning (ML) techniques to evaluate the glass transition temperature Tg and other properties of polymers has attracted extensive attention. This data-centric approach is much more efficient and practical than the laborious experimental measurements when encountered a daunting number of polymer structures. Various ML models are demonstrated to perform well for Tg prediction. Nevertheless, they are trained on different data sets, using different structure representations, and based on different feature engineering methods. Thus, the critical question arises on selecting a proper ML model to better handle the Tg prediction with generalization ability. To provide a fair comparison of different ML techniques and examine the key factors that affect the model performance, we carry out a systematic benchmark study by compiling 79 different ML models and training them on a large and diverse data set. The three major components in setting up an ML model are structure representations, feature representations, and ML algorithms. In terms of polymer structure representation, we consider the polymer monomer, repeat unit, and oligomer with longer chain structure. Based on that feature, representation is calculated, including Morgan fingerprinting with or without substructure frequency, RDKit descriptors, molecular embedding, molecular graph, etc. Afterward, the obtained feature input is trained using different ML algorithms, such as deep neural networks, convolutional neural networks, random forest, support vector machine, LASSO regression, and Gaussian process regression. We evaluate the performance of these ML models using a holdout test set and an extra unlabeled data set from high-throughput molecular dynamics simulation. The ML model’s generalization ability on an unlabeled data set is especially focused, and the model’s sensitivity to topology and the molecular weight of polymers is also taken into consideration. This benchmark study provides not only a guideline for the Tg prediction task but also a useful reference for other polymer informatics tasks.
中文翻译:

聚合物信息学的基准机器学习模型:玻璃化转变温度的一个例子
在聚合物信息学领域,利用机器学习(ML)技术评估聚合物的玻璃化转变温度T g等特性已引起广泛关注。当遇到数量惊人的聚合物结构时,这种以数据为中心的方法比费力的实验测量更有效和实用。各种 ML 模型被证明在T g预测方面表现良好。然而,它们是在不同的数据集上训练的,使用不同的结构表示,并基于不同的特征工程方法。因此,关键的问题是如何选择适当的ML模型以更好地处理Ť克具有泛化能力的预测。为了公平比较不同的 ML 技术并检查影响模型性能的关键因素,我们通过编译 79 个不同的 ML 模型并在大量不同的数据集上训练它们来进行系统的基准研究。建立机器学习模型的三个主要组成部分是结构表示、特征表示和机器学习算法。在聚合物结构表示方面,我们考虑具有较长链结构的聚合物单体、重复单元和低聚物。基于该特征,计算表征,包括有或没有子结构频率的摩根指纹、RDKit 描述符、分子嵌入、分子图等。然后,使用不同的 ML 算法训练获得的特征输入,例如深度神经网络,卷积神经网络、随机森林、支持向量机、LASSO 回归和高斯过程回归。我们使用保持测试集和来自高通量分子动力学模拟的额外未标记数据集来评估这些 ML 模型的性能。ML 模型对未标记数据集的泛化能力尤为突出,并且还考虑了模型对拓扑和聚合物分子量的敏感性。这项基准研究不仅为 ML 模型对未标记数据集的泛化能力尤为突出,并且还考虑了模型对拓扑和聚合物分子量的敏感性。这项基准研究不仅为 ML 模型对未标记数据集的泛化能力尤为突出,并且还考虑了模型对拓扑和聚合物分子量的敏感性。这项基准研究不仅为T g预测任务也是其他聚合物信息学任务的有用参考。
更新日期:2021-11-22
中文翻译:
聚合物信息学的基准机器学习模型:玻璃化转变温度的一个例子
在聚合物信息学领域,利用机器学习(ML)技术评估聚合物的玻璃化转变温度T g等特性已引起广泛关注。当遇到数量惊人的聚合物结构时,这种以数据为中心的方法比费力的实验测量更有效和实用。各种 ML 模型被证明在T g预测方面表现良好。然而,它们是在不同的数据集上训练的,使用不同的结构表示,并基于不同的特征工程方法。因此,关键的问题是如何选择适当的ML模型以更好地处理Ť克具有泛化能力的预测。为了公平比较不同的 ML 技术并检查影响模型性能的关键因素,我们通过编译 79 个不同的 ML 模型并在大量不同的数据集上训练它们来进行系统的基准研究。建立机器学习模型的三个主要组成部分是结构表示、特征表示和机器学习算法。在聚合物结构表示方面,我们考虑具有较长链结构的聚合物单体、重复单元和低聚物。基于该特征,计算表征,包括有或没有子结构频率的摩根指纹、RDKit 描述符、分子嵌入、分子图等。然后,使用不同的 ML 算法训练获得的特征输入,例如深度神经网络,卷积神经网络、随机森林、支持向量机、LASSO 回归和高斯过程回归。我们使用保持测试集和来自高通量分子动力学模拟的额外未标记数据集来评估这些 ML 模型的性能。ML 模型对未标记数据集的泛化能力尤为突出,并且还考虑了模型对拓扑和聚合物分子量的敏感性。这项基准研究不仅为 ML 模型对未标记数据集的泛化能力尤为突出,并且还考虑了模型对拓扑和聚合物分子量的敏感性。这项基准研究不仅为 ML 模型对未标记数据集的泛化能力尤为突出,并且还考虑了模型对拓扑和聚合物分子量的敏感性。这项基准研究不仅为T g预测任务也是其他聚合物信息学任务的有用参考。









































 京公网安备 11010802027423号
京公网安备 11010802027423号