Econometric Theory ( IF 1.0 ) Pub Date : 2021-09-27 , DOI: 10.1017/s026646662100044x Hannes Leeb 1 , Lukas Steinberger 2
We study linear subset regression in the context of the high-dimensional overall model 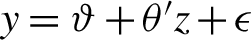 $y = \vartheta +\theta ' z + \epsilon $ with univariate response y and a d-vector of random regressors z, independent of
$y = \vartheta +\theta ' z + \epsilon $ with univariate response y and a d-vector of random regressors z, independent of 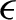 $\epsilon $. Here, “high-dimensional” means that the number d of available explanatory variables is much larger than the number n of observations. We consider simple linear submodels where y is regressed on a set of p regressors given by
$\epsilon $. Here, “high-dimensional” means that the number d of available explanatory variables is much larger than the number n of observations. We consider simple linear submodels where y is regressed on a set of p regressors given by 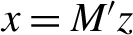 $x = M'z$, for some
$x = M'z$, for some  $d \times p$ matrix M of full rank
$d \times p$ matrix M of full rank  $p < n$. The corresponding simple model, that is,
$p < n$. The corresponding simple model, that is, 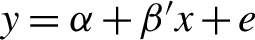 $y=\alpha +\beta ' x + e$, is usually justified by imposing appropriate restrictions on the unknown parameter
$y=\alpha +\beta ' x + e$, is usually justified by imposing appropriate restrictions on the unknown parameter 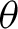 $\theta $ in the overall model; otherwise, this simple model can be grossly misspecified in the sense that relevant variables may have been omitted. In this paper, we establish asymptotic validity of the standard F-test on the surrogate parameter
$\theta $ in the overall model; otherwise, this simple model can be grossly misspecified in the sense that relevant variables may have been omitted. In this paper, we establish asymptotic validity of the standard F-test on the surrogate parameter 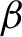 $\beta $, in an appropriate sense, even when the simple model is misspecified, that is, without any restrictions on
$\beta $, in an appropriate sense, even when the simple model is misspecified, that is, without any restrictions on 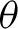 $\theta $ whatsoever and without assuming Gaussian data.
$\theta $ whatsoever and without assuming Gaussian data.
中文翻译:
将简单模型拟合到高维数据时使用 F 统计量进行统计推断
我们在高维总体模型$y = \vartheta +\theta ' z + \epsilon $的背景下研究线性子集回归,其中单变量响应y和随机回归量z的d向量,独立于$\epsilon $。这里,“高维”是指可用解释变量的数量d远大于观测值的数量n。我们考虑简单的线性子模型,其中y在由$x = M'z$给出的一组p回归量上进行回归,对于满秩$p < n$的某些$d \times p$矩阵M。相应的简单模型,即$y=\alpha +\beta ' x + e$,通常通过对整体模型中的未知参数$\theta $施加适当的限制来证明其合理性;否则,这个简单的模型可能会被严重错误指定,因为相关变量可能已被省略。在本文中,我们在适当的意义上建立了对代理参数$\beta $的标准F检验的渐近有效性,即使简单模型被错误指定,即对$\theta $没有任何限制,并且没有假设高斯数据。










































 京公网安备 11010802027423号
京公网安备 11010802027423号