Information Fusion ( IF 14.7 ) Pub Date : 2021-09-20 , DOI: 10.1016/j.inffus.2021.09.014 Manuel Lopez-Martin 1 , Antonio Sanchez-Esguevillas 1 , Juan Ignacio Arribas 1, 2 , Belen Carro 1
|
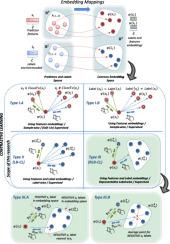
Contrastive learning makes it possible to establish similarities between samples by comparing their distances in an intermediate representation space (embedding space) and using loss functions designed to attract/repel similar/dissimilar samples. The distance comparison is based exclusively on the sample features. We propose a novel contrastive learning scheme by including the labels in the same embedding space as the features and performing the distance comparison between features and labels in this shared embedding space. Following this idea, the sample features should be close to its ground-truth (positive) label and away from the other labels (negative labels). This scheme allows to implement a supervised classification based on contrastive learning. Each embedded label will assume the role of a class prototype in embedding space, with sample features that share the label gathering around it. The aim is to separate the label prototypes while minimizing the distance between each prototype and its same-class samples. A novel set of loss functions is proposed with this objective. Loss minimization will drive the allocation of sample features and labels in embedding space. Loss functions and their associated training and prediction architectures are analyzed in detail, along with different strategies for label separation. The proposed scheme drastically reduces the number of pair-wise comparisons, thus improving model performance. In order to further reduce the number of pair-wise comparisons, this initial scheme is extended by replacing the set of negative labels by its best single representative: either the negative label nearest to the sample features or the centroid of the cluster of negative labels. This idea creates a new subset of models which are analyzed in detail.
The outputs of the proposed models are the distances (in embedding space) between each sample and the label prototypes. These distances can be used to perform classification (minimum distance label), features dimensionality reduction (using the distances and the embeddings instead of the original features) and data visualization (with 2 or 3D embeddings).
Although the proposed models are generic, their application and performance evaluation is done here for network intrusion detection, characterized by noisy and unbalanced labels and a challenging classification of the various types of attacks. Empirical results of the model applied to intrusion detection are presented in detail for two well-known intrusion detection datasets, and a thorough set of classification and clustering performance evaluation metrics are included.
中文翻译:
用于网络入侵检测的原型标签嵌入的监督对比学习
对比学习可以通过比较样本在中间表示空间(嵌入空间)中的距离并使用旨在吸引/排斥相似/不同样本的损失函数来建立样本之间的相似性。距离比较完全基于样本特征。我们提出了一种新颖的对比学习方案,将标签包含在与特征相同的嵌入空间中,并在此共享嵌入空间中执行特征和标签之间的距离比较。按照这个想法,样本特征应该接近其真实(正)标签并远离其他标签(负标签)。该方案允许实现基于对比学习的监督分类。每个嵌入的标签将承担嵌入空间中类原型的角色,具有共享标签的示例特征聚集在它周围。目的是分离标签原型,同时最小化每个原型与其同类样本之间的距离。为此目的提出了一组新的损失函数。损失最小化将推动嵌入空间中样本特征和标签的分配。详细分析了损失函数及其相关的训练和预测架构,以及不同的标签分离策略。所提出的方案大大减少了成对比较的次数,从而提高了模型性能。为了进一步减少成对比较的次数,这个初始方案通过用最好的单一代表替换负标签集来扩展:最接近样本特征的负标签或负标签集群的质心。这个想法创建了一个新的模型子集,这些模型被详细分析。
所提出模型的输出是每个样本与标签原型之间的距离(在嵌入空间中)。这些距离可用于执行分类(最小距离标签)、特征降维(使用距离和嵌入代替原始特征)和数据可视化(使用 2 或 3D 嵌入)。
尽管所提出的模型是通用的,但它们的应用和性能评估是针对网络入侵检测进行的,其特征是噪声和不平衡的标签以及对各种攻击类型的挑战性分类。针对两个著名的入侵检测数据集,详细介绍了应用于入侵检测的模型的实证结果,并包括了一套完整的分类和聚类性能评估指标。










































 京公网安备 11010802027423号
京公网安备 11010802027423号