Knowledge-Based Systems ( IF 7.2 ) Pub Date : 2021-09-11 , DOI: 10.1016/j.knosys.2021.107469 Antonio Lopez-Martinez-Carrasco 1 , Jose M. Juarez 1 , Manuel Campos 1, 2 , Bernardo Canovas-Segura 1
|
Background:
The current situation of critical progression as regards the resistance of bacteria to antibiotics has led to the use of machine learning techniques in order to provide clinicians with new knowledge for decision making. One of the key aspects is precision medicine, which focuses on finding phenotypes of patients for whom treatments may be more effective or detecting high risk patients whose progress must be closely monitored. The identification of these phenotypes requires the application of a methodology whose results are consistent and interpretable, along with the control of the process by a clinical expert. Studies concerning machine learning phenotyping use conventional clustering or subgroup algorithms that require information to be obtained a priori.
Methods:
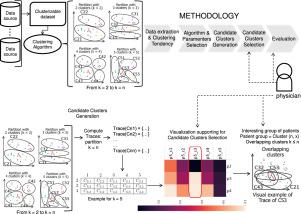
We propose a new unsupervised machine learning technique, denominated as Trace-based clustering, and a 5-step methodology in order to support clinicians when identifying patient phenotypes. The steps proposed are: (1) Extraction and transformation of data and analysis of clustering tendency, (2) Selection of clustering algorithm and parameters, (3) Automatic generation of candidate clusters, (4) Visual support for selection of candidate clusters, and (5) Evaluation by clinical experts.
Experiments and Results:
We undertake an antimicrobial resistance use case by employing the MIMIC-III open-access database for patients infected with the Methicillin-resistant Staphylococcus Aereus and Enterococcus Faecium treated with Vancomycin. The experiments were carried out using the Hopkins statistic in order to evaluate the clustering tendency of the data, the K-Means algorithm for clustering, and the Dice coefficient to measure the similarity of the clusters. Our experiments computed 370 potential patient sets (clusters) so as to obtain 19 candidate clusters for their final evaluation. We evaluated the final result with a classification model in order to ensure the consistency of the phenotypes obtained and we compared the result with a traditional clustering approach. We found a reduced set of consistent candidate clusters with a common phenotype (resistance and death), which were different from the other candidate clusters. An expert in the domain could add labels with clinical meaning to the reduced number of clusters.
Conclusions:
We show that the proposed methodology allows physicians to identify consistent patient phenotypes. Our experiments confirm that quality measures, and the visual analysis could help expert clinicians to control the knowledge discovery process and obtain interpretable results. Our approach provides a new perspective: that of finding patient sets using clustering techniques evaluated by overlapping clusters of the previous partitions. The method proposed is general and can be easily adapted to any other problem and any other clinical settings.
中文翻译:
一种基于 Trace-based clustering 的患者表型分析方法
背景:
目前细菌对抗生素耐药性的严重进展导致使用机器学习技术,以便为临床医生提供新的决策知识。其中一个关键方面是精准医学,其重点是发现治疗可能更有效的患者的表型,或检测必须密切监测进展的高风险患者。这些表型的鉴定需要应用结果一致且可解释的方法,以及临床专家对过程的控制。有关机器学习表型的研究使用需要先验获取信息的传统聚类或子组算法。
方法:
我们提出了一种新的无监督机器学习技术,称为基于跟踪的聚类,以及一种 5 步方法,以便在识别患者表型时支持临床医生。提出的步骤是:(1)数据的提取和转化,聚类趋势分析,(2)聚类算法和参数的选择,(3)候选聚类的自动生成,(4)候选聚类选择的视觉支持,以及(5)临床专家评价。
实验和结果:
我们针对感染了耐甲氧西林金黄色葡萄球菌和用万古霉素治疗的屎肠球菌的患者使用 MIMIC-III 开放访问数据库,进行了抗菌素耐药性用例。使用 Hopkins 统计量进行实验以评估数据的聚类趋势,使用 K-Means 算法进行聚类,并使用 Dice 系数来衡量聚类的相似性。我们的实验计算了 370 个潜在的患者集(集群),以获得 19 个候选集群进行最终评估。我们使用分类模型评估最终结果,以确保获得的表型的一致性,并将结果与传统聚类方法进行比较。我们发现了一组减少的具有共同表型(耐药性和死亡)的一致候选簇,它们与其他候选簇不同。该领域的专家可以为减少的集群数量添加具有临床意义的标签。
结论:
我们表明,所提出的方法允许医生识别一致的患者表型。我们的实验证实了质量测量和可视化分析可以帮助专家临床医生控制知识发现过程并获得可解释的结果。我们的方法提供了一个新的视角:使用由先前分区的重叠集群评估的聚类技术来查找患者集。所提出的方法是通用的,可以很容易地适应任何其他问题和任何其他临床环境。










































 京公网安备 11010802027423号
京公网安备 11010802027423号