Forensic Chemistry ( IF 2.6 ) Pub Date : 2021-09-07 , DOI: 10.1016/j.forc.2021.100358 Michael E. Sigman 1 , Mary R. Williams 1 , Nicholas Thurn 1 , Taylor Wood 1
|
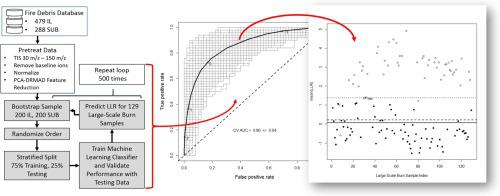
A set of 767 laboratory-generated fire debris samples of known ground truth as to whether an ignitable liquid residue was present (class IL) or absent (class SUB) were used to train five machine learning classifiers. Linear and quadratic discriminant analysis (LDA and QDA), k-nearest neighbors (kNN), and support vector machines with radial and linear kernels (SVMr and SVMl) were tested for their performance in correctly classifying the fire debris samples into class IL or class SUB. Each classifier was trained and tested/validated on 500 class-balanced data sets, each comprised of 400 fire debris samples (200 IL and 200 SUB) that were bootstrapped from the 767 laboratory-generated samples. Each bootstrapped data set was split into subsets for training (75%, 300 samples) and testing/validation (25%, 100 samples). The LDA, SVMr and SVMl were found to give satisfactory performance based on area under the receiver operating characteristic curve (0.86–0.92), equal error rates (17%−22%) and well-calibrated probabilities. The three satisfactory classifiers were further applied to a set of 129 fire debris samples produced in large-scale test burns. The classifications generated by the machine learning models were compared with the sample classes assigned by an informed analyst having knowledge of the chromatographic patterns of the ignitable liquids use to start the large-scale fires. The LDA and SVMl models gave results most closely aligned with the informed analyst.
中文翻译:
通过监督机器学习验证地面真实火灾碎片分类
一组 767 个实验室生成的火灾碎片样本,其已知地面实况关于是否存在可燃液体残留物(IL 类)或不存在(SUB 类)被用于训练五个机器学习分类器。线性和二次判别分析(LDA 和 QDA)、k-最近邻 (kNN) 以及具有径向和线性核的支持向量机(SVM r和 SVM l) 测试了它们在将火灾碎片样本正确分类为 IL 类或 SUB 类方面的性能。每个分类器都在 500 个类平衡数据集上进行了训练和测试/验证,每个数据集包含 400 个火灾碎片样本(200 个 IL 和 200 个 SUB),这些样本是从 767 个实验室生成的样本中提取的。每个自举数据集被分成用于训练(75%,300 个样本)和测试/验证(25%,100 个样本)的子集。LDA、SVM r和 SVM l发现基于接收器操作特征曲线下的面积 (0.86–0.92)、相等的错误率 (17%-22%) 和校准良好的概率提供了令人满意的性能。这三个令人满意的分类器进一步应用于在大规模测试烧伤中产生的一组 129 个火灾碎片样本。将机器学习模型生成的分类与了解用于引发大规模火灾的可燃液体的色谱模式的知情分析师分配的样本类别进行比较。LDA 和 SVM l模型给出的结果与知情分析师最接近。










































 京公网安备 11010802027423号
京公网安备 11010802027423号