当前位置:
X-MOL 学术
›
Anal. Methods
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Beyond principal components: a critical comparison of factor analysis methods for subspace modelling in chemistry
Analytical Methods ( IF 2.7 ) Pub Date : 2021-08-27 , DOI: 10.1039/d1ay01124c Peter D Wentzell 1 , Cannon Giglio 1 , Mohsen Kompany-Zareh 1, 2
Analytical Methods ( IF 2.7 ) Pub Date : 2021-08-27 , DOI: 10.1039/d1ay01124c Peter D Wentzell 1 , Cannon Giglio 1 , Mohsen Kompany-Zareh 1, 2
Affiliation
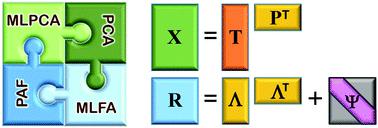
|
Multivariate data analysis tools have become an integral part of modern analytical chemistry, and principal component analysis (PCA) is perhaps foremost among these. PCA is central in approaching many problems in data exploration, classification, calibration, modelling, and curve resolution. However, PCA is only one form of a broader group of factor analysis (FA) methods that are rarely employed by chemists. The dominance of PCA in chemistry is primarily a consequence of history and convenience, but this has obscured the potential advantages of other FA tools that are widely used in other fields. The purpose of this article, which is intended for those who are already familiar with the mathematical foundations and applications of PCA, is to develop a framework to relate PCA to other commonly used FA methods from the perspective of chemical applications. Specifically, PCA is compared to maximum likelihood factor analysis (MLFA), principal axis factorization (PAF) and maximum likelihood PCA (MLPCA). Similarities and differences are highlighted with regard to the assumptions and constraints of the models, algorithms employed, and calculation of scores and loadings. Practical aspects such as data dimensionality, preprocessing, rank estimation, improper solutions (Heywood cases), and software implementation are considered. The performance of the four methods is compared using both simulated and experimental data sets. While PCA provides the most reliable estimates when measurement error variance is uniform (homoscedastic noise) and MLPCA works best when the error covariance matrix is explicitly known, MLFA and PAF have the distinct advantage of providing information about measurement uncertainty and adapting to situations of unknown heteroscedastic errors, eliminating the need for scaling. Moreover, MLFA in particular is shown to be tolerant to deviations from model linearity. These results make a strong case for increased application of other FA methods in chemistry.
中文翻译:

超越主成分:化学子空间建模的因子分析方法的关键比较
多元数据分析工具已成为现代分析化学不可或缺的一部分,其中主成分分析 (PCA) 可能是最重要的。PCA 是解决数据探索、分类、校准、建模和曲线解析中的许多问题的核心。然而,PCA 只是化学家很少采用的更广泛的一组因子分析 (FA) 方法的一种形式。PCA 在化学中的主导地位主要是历史和便利的结果,但这掩盖了在其他领域广泛使用的其他 FA 工具的潜在优势。本文的目的是为那些已经熟悉 PCA 的数学基础和应用的人准备的,是开发一个框架,从化学应用的角度将 PCA 与其他常用的 FA 方法联系起来。具体而言,将 PCA 与最大似然因子分析 (MLFA)、主轴分解 (PAF) 和最大似然 PCA (MLPCA) 进行比较。在模型的假设和约束、采用的算法以及分数和负载的计算方面突出了异同。考虑了数据维度、预处理、秩估计、不当解决方案(Heywood 案例)和软件实现等实际方面。使用模拟和实验数据集比较了四种方法的性能。虽然 PCA 在测量误差方差均匀(同方差噪声)时提供最可靠的估计,而当误差协方差矩阵明确已知时 MLPCA 效果最佳,但 MLFA 和 PAF 具有独特的优势,可提供有关测量不确定性的信息并适应未知异方差的情况错误,消除了缩放的需要。此外,特别是 MLFA 被证明可以容忍模型线性的偏差。这些结果为增加其他 FA 方法在化学中的应用提供了强有力的理由。特别是 MLFA 被证明可以容忍模型线性的偏差。这些结果为增加其他 FA 方法在化学中的应用提供了强有力的理由。特别是 MLFA 被证明可以容忍模型线性的偏差。这些结果为增加其他 FA 方法在化学中的应用提供了强有力的理由。
更新日期:2021-09-02
中文翻译:
超越主成分:化学子空间建模的因子分析方法的关键比较
多元数据分析工具已成为现代分析化学不可或缺的一部分,其中主成分分析 (PCA) 可能是最重要的。PCA 是解决数据探索、分类、校准、建模和曲线解析中的许多问题的核心。然而,PCA 只是化学家很少采用的更广泛的一组因子分析 (FA) 方法的一种形式。PCA 在化学中的主导地位主要是历史和便利的结果,但这掩盖了在其他领域广泛使用的其他 FA 工具的潜在优势。本文的目的是为那些已经熟悉 PCA 的数学基础和应用的人准备的,是开发一个框架,从化学应用的角度将 PCA 与其他常用的 FA 方法联系起来。具体而言,将 PCA 与最大似然因子分析 (MLFA)、主轴分解 (PAF) 和最大似然 PCA (MLPCA) 进行比较。在模型的假设和约束、采用的算法以及分数和负载的计算方面突出了异同。考虑了数据维度、预处理、秩估计、不当解决方案(Heywood 案例)和软件实现等实际方面。使用模拟和实验数据集比较了四种方法的性能。虽然 PCA 在测量误差方差均匀(同方差噪声)时提供最可靠的估计,而当误差协方差矩阵明确已知时 MLPCA 效果最佳,但 MLFA 和 PAF 具有独特的优势,可提供有关测量不确定性的信息并适应未知异方差的情况错误,消除了缩放的需要。此外,特别是 MLFA 被证明可以容忍模型线性的偏差。这些结果为增加其他 FA 方法在化学中的应用提供了强有力的理由。特别是 MLFA 被证明可以容忍模型线性的偏差。这些结果为增加其他 FA 方法在化学中的应用提供了强有力的理由。特别是 MLFA 被证明可以容忍模型线性的偏差。这些结果为增加其他 FA 方法在化学中的应用提供了强有力的理由。










































 京公网安备 11010802027423号
京公网安备 11010802027423号