当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Machine Learning-Enabled Pipeline for Large-Scale Virtual Drug Screening
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2021-08-17 , DOI: 10.1021/acs.jcim.1c00710 Aayush Gupta 1 , Huan-Xiang Zhou 1, 2
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2021-08-17 , DOI: 10.1021/acs.jcim.1c00710 Aayush Gupta 1 , Huan-Xiang Zhou 1, 2
Affiliation
|
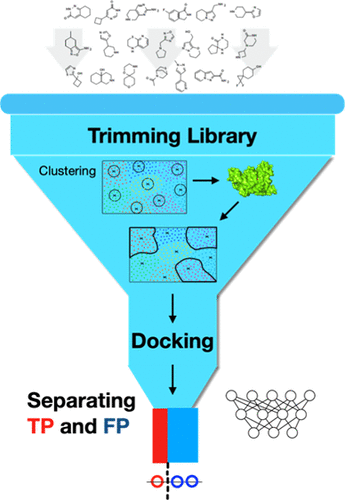
Virtual screening is receiving renewed attention in drug discovery, but progress is hampered by challenges on two fronts: handling the ever-increasing sizes of libraries of drug-like compounds and separating true positives from false positives. Here, we developed a machine learning-enabled pipeline for large-scale virtual screening that promises breakthroughs on both fronts. By clustering compounds according to molecular properties and limited docking against a drug target, the full library was trimmed by 10-fold; the remaining compounds were then screened individually by docking; and finally, a dense neural network was trained to classify the hits into true and false positives. As illustration, we screened for inhibitors against RPN11, the deubiquitinase subunit of the proteasome, and a drug target for breast cancer.
中文翻译:

用于大规模虚拟药物筛选的机器学习管道
虚拟筛选在药物发现中得到了新的关注,但进展受到两个方面的挑战的阻碍:处理不断增加的类药物化合物库以及区分真阳性和假阳性。在这里,我们开发了一种支持机器学习的管道,用于大规模虚拟筛选,有望在两个方面取得突破。通过根据分子特性对化合物进行聚类并限制与药物靶点的对接,整个库被修剪了 10 倍;然后通过对接单独筛选剩余的化合物;最后,训练一个密集的神经网络,将命中分类为真假阳性。作为说明,我们筛选了针对 RPN11(蛋白酶体的去泛素酶亚基)和乳腺癌药物靶点的抑制剂。
更新日期:2021-09-27
中文翻译:
用于大规模虚拟药物筛选的机器学习管道
虚拟筛选在药物发现中得到了新的关注,但进展受到两个方面的挑战的阻碍:处理不断增加的类药物化合物库以及区分真阳性和假阳性。在这里,我们开发了一种支持机器学习的管道,用于大规模虚拟筛选,有望在两个方面取得突破。通过根据分子特性对化合物进行聚类并限制与药物靶点的对接,整个库被修剪了 10 倍;然后通过对接单独筛选剩余的化合物;最后,训练一个密集的神经网络,将命中分类为真假阳性。作为说明,我们筛选了针对 RPN11(蛋白酶体的去泛素酶亚基)和乳腺癌药物靶点的抑制剂。










































 京公网安备 11010802027423号
京公网安备 11010802027423号