Information Fusion ( IF 14.7 ) Pub Date : 2021-08-16 , DOI: 10.1016/j.inffus.2021.07.005 Jose M. Moyano 1 , Sebastián Ventura 1
|
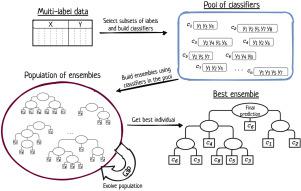
Multi-label classification has been used to solve a wide range of problems where each example in the dataset may be related either to one class (as in traditional classification problems) or to several class labels at the same time. Many ensemble-based approaches have been proposed in the literature, aiming to improve the performance of traditional multi-label classification algorithms. However, most of them do not consider the data characteristics to build the ensemble, and those that consider them need to tune many parameters to maximize their performance.
In this paper, we propose an Auto-adaptive algorithm based on Grammar-Guided Genetic Programming to generate Ensembles of Multi-Label Classifiers based on projections of labels (AG3P-kEMLC). It creates a tree-shaped ensemble, where each leaf is a multi-label classifier focused on a subset of labels. Unlike other methods in the literature, our proposal can deal with different values of in the same ensemble, instead of fixing one specific value. It also includes an auto-adaptive process to reduce the number of hyper-parameters to tune, prevent overfitting and reduce the runtime required to execute it. Three versions of the algorithm are proposed. The first, fixed, uses the same value of for all multi-label classifiers in the ensemble. The remaining two deal with different values in the ensemble: uniform gives the same probability to choose each available value of , and gaussian favors the selection of smaller values of .
The experimental study carried out considering twenty reference datasets and five evaluation metrics, compared with eleven ensemble methods demonstrates that our proposal performs significantly better than the state-of-the-art methods.
中文翻译:
用于构建多标签分类器集成的自适应语法引导遗传编程算法
多标签分类已被用于解决范围广泛的问题,其中数据集中的每个示例可能与一个类(如在传统分类问题中)或同时与多个类标签相关。文献中提出了许多基于集成的方法,旨在提高传统多标签分类算法的性能。然而,他们中的大多数没有考虑数据特征来构建集成,而那些考虑它们的人需要调整许多参数以最大化其性能。
在本文中,我们提出了一种基于语法引导遗传编程的自适应算法,以基于投影生成多标签分类器的集合。 标签(AG3P-kEMLC)。它创建了一个树形集成,其中每个叶子都是一个多标签分类器,专注于标签。与文献中的其他方法不同,我们的建议可以处理不同的值在同一个整体中,而不是固定一个特定的值。它还包括一个自适应过程,以减少要调整的超参数的数量,防止过度拟合并减少执行所需的运行时间。提出了该算法的三个版本。第一个,fixed,使用相同的值对于集成中的所有多标签分类器。剩下的两个处理不同整体中的值:uniform给出了选择每个可用值的相同概率,高斯倾向于选择较小的值.
考虑到 20 个参考数据集和 5 个评估指标进行的实验研究,与 11 个集成方法相比,表明我们的提议明显优于最先进的方法。










































 京公网安备 11010802027423号
京公网安备 11010802027423号