当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Systematic Investigation of Error Distribution in Machine Learning Algorithms Applied to the Quantum-Chemistry QM9 Data Set Using the Bias and Variance Decomposition
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2021-08-13 , DOI: 10.1021/acs.jcim.1c00503 Luis Cesar de Azevedo 1 , Gabriel A Pinheiro 2 , Marcos G Quiles 2 , Juarez L F Da Silva 3 , Ronaldo C Prati 1
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2021-08-13 , DOI: 10.1021/acs.jcim.1c00503 Luis Cesar de Azevedo 1 , Gabriel A Pinheiro 2 , Marcos G Quiles 2 , Juarez L F Da Silva 3 , Ronaldo C Prati 1
Affiliation
|
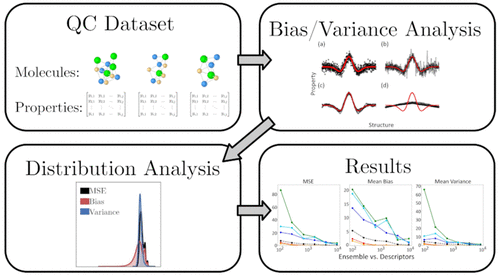
Most machine learning applications in quantum-chemistry (QC) data sets rely on a single statistical error parameter such as the mean square error (MSE) to evaluate their performance. However, this approach has limitations or can even yield incorrect interpretations. Here, we report a systematic investigation of the two components of the MSE, i.e., the bias and variance, using the QM9 data set. To this end, we experiment with three descriptors, namely (i) symmetry functions (SF, with two-body and three-body functions), (ii) many-body tensor representation (MBTR, with two- and three-body terms), and (iii) smooth overlap of atomic positions (SOAP), to evaluate the prediction process’s performance using different numbers of molecules in training samples and the effect of bias and variance on the final MSE. Overall, low sample sizes are related to higher MSE. Moreover, the bias component strongly influences the larger MSEs. Furthermore, there is little agreement among molecules with higher errors (outliers) across different descriptors. However, there is a high prevalence among the outliers intersection set and the convex hull volume of geometric coordinates (VCH). According to the obtained results with the distribution of MSE (and its components bias and variance) and the appearance of outliers, it is suggested to use ensembles of models with a low bias to minimize the MSE, more specifically when using a small number of molecules in the training set.
中文翻译:

使用偏差和方差分解对应用于量子化学 QM9 数据集的机器学习算法中的误差分布进行系统研究
量子化学 (QC) 数据集中的大多数机器学习应用程序都依赖于单个统计误差参数(例如均方误差 (MSE))来评估其性能。然而,这种方法有局限性,甚至会产生错误的解释。在这里,我们报告了使用 QM9 数据集对 MSE 的两个组成部分(即偏差和方差)进行的系统调查。为此,我们试验了三个描述符,即(i)对称函数(SF,具有二体和三体函数),(ii)多体张量表示(MBTR,具有二体和三体项) ,以及 (iii) 原子位置的平滑重叠 (SOAP),以使用训练样本中不同数量的分子来评估预测过程的性能以及偏差和方差对最终 MSE 的影响。总体,低样本量与较高的 MSE 相关。此外,偏置分量强烈影响较大的 MSE。此外,在不同描述符中具有较高误差(异常值)的分子之间几乎没有一致性。然而,异常值交叉集和几何坐标凸包体积(VCH)之间的流行率很高。根据获得的 MSE 分布(及其分量偏差和方差)和异常值出现的结果,建议使用具有低偏差的模型集合来最小化 MSE,尤其是在使用少量分子时在训练集中。离群值交叉集和几何坐标凸包体积(VCH)之间的流行率很高。根据获得的 MSE 分布(及其分量偏差和方差)和异常值出现的结果,建议使用具有低偏差的模型集合来最小化 MSE,尤其是在使用少量分子时在训练集中。离群值交叉集和几何坐标凸包体积(VCH)之间的流行率很高。根据获得的 MSE 分布(及其分量偏差和方差)和异常值出现的结果,建议使用具有低偏差的模型集合来最小化 MSE,尤其是在使用少量分子时在训练集中。
更新日期:2021-09-27
中文翻译:
使用偏差和方差分解对应用于量子化学 QM9 数据集的机器学习算法中的误差分布进行系统研究
量子化学 (QC) 数据集中的大多数机器学习应用程序都依赖于单个统计误差参数(例如均方误差 (MSE))来评估其性能。然而,这种方法有局限性,甚至会产生错误的解释。在这里,我们报告了使用 QM9 数据集对 MSE 的两个组成部分(即偏差和方差)进行的系统调查。为此,我们试验了三个描述符,即(i)对称函数(SF,具有二体和三体函数),(ii)多体张量表示(MBTR,具有二体和三体项) ,以及 (iii) 原子位置的平滑重叠 (SOAP),以使用训练样本中不同数量的分子来评估预测过程的性能以及偏差和方差对最终 MSE 的影响。总体,低样本量与较高的 MSE 相关。此外,偏置分量强烈影响较大的 MSE。此外,在不同描述符中具有较高误差(异常值)的分子之间几乎没有一致性。然而,异常值交叉集和几何坐标凸包体积(VCH)之间的流行率很高。根据获得的 MSE 分布(及其分量偏差和方差)和异常值出现的结果,建议使用具有低偏差的模型集合来最小化 MSE,尤其是在使用少量分子时在训练集中。离群值交叉集和几何坐标凸包体积(VCH)之间的流行率很高。根据获得的 MSE 分布(及其分量偏差和方差)和异常值出现的结果,建议使用具有低偏差的模型集合来最小化 MSE,尤其是在使用少量分子时在训练集中。离群值交叉集和几何坐标凸包体积(VCH)之间的流行率很高。根据获得的 MSE 分布(及其分量偏差和方差)和异常值出现的结果,建议使用具有低偏差的模型集合来最小化 MSE,尤其是在使用少量分子时在训练集中。










































 京公网安备 11010802027423号
京公网安备 11010802027423号