Information Fusion ( IF 18.6 ) Pub Date : 2021-08-02 , DOI: 10.1016/j.inffus.2021.07.014 Sebastian Kiefer 1
|
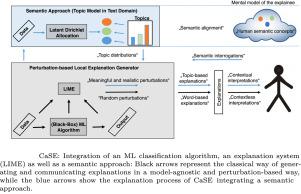
Generating explanations within a local and model-agnostic explanation scenario for text classification is often accompanied by a local approximation task. In order to create a local neighborhood for a document, whose classification shall be explained, sampling techniques are used that most often treat the according features at least semantically independent from each other. Hence, contextual as well as semantic information is lost and therefore cannot be used to update a human’s mental model within the according explanation task. In case of dependent features, such explanation techniques are prone to extrapolation to feature areas with low data density, therefore causing misleading interpretations. Additionally, the ”the whole is greater than the sum of its parts” phenomenon is disregarded when using explanations that treat the according words independently from each other. In this paper, an architecture named CaSE is proposed that either uses Semantic Feature Arrangements or Semantic Interrogations to overcome these drawbacks. Combined with a modified version of Local interpretable model-agnostic explanations (LIME), a state of the art local explanation framework, it is capable of generating meaningful and coherent explanations. The approach utilizes contextual and semantic knowledge from unsupervised topic models in order to enable realistic and semantic sampling and based on that generate understandable explanations for any text classifier. The key concepts of CaSE that are deemed essential for providing humans with high quality explanations are derived from findings of psychology. In a nutshell, CaSE shall enable Semantic Alignment between humans and machines and thus further improve the basis for Interactive Machine Learning. An extensive experimental validation of CaSE is conducted, showing its effectiveness by generating reliable and meaningful explanations whose elements are made of contextually coherent words and therefore are suitable to update human mental models in an appropriate way. In the course of a quantitative analysis, the proposed architecture is evaluated w.r.t. a consistency property and to Local Fidelity of the resulting explanation models. According to that, CaSE generates more realistic explanation models leading to higher Local Fidelity compared to LIME.
中文翻译:
案例:通过将局部代理解释模型与上下文和语义知识融合来解释文本分类
在文本分类的局部和模型不可知解释场景中生成解释通常伴随着局部逼近任务。为了为文档创建局部邻域,其分类将被解释,使用采样技术最常处理相应的特征,至少在语义上彼此独立。因此,上下文和语义信息都丢失了,因此不能用于在相应的解释任务中更新人类的心理模型。在依赖特征的情况下,这种解释技术容易外推到数据密度低的特征区域,从而导致误导性解释。此外,在使用相互独立对待相应词的解释时,“整体大于部分之和”现象被忽略。在本文中,提出了一种名为 CaSE 的架构,它使用语义特征排列或语义询问来克服这些缺点。结合本地可解释模型不可知解释 (LIME) 的修改版本,这是一种最先进的本地解释框架,它能够生成有意义且连贯的解释。该方法利用来自无监督主题模型的上下文和语义知识,以实现现实和语义采样,并在此基础上为任何文本分类器生成可理解的解释。被认为对于为人类提供高质量解释必不可少的 CaSE 的关键概念来自心理学的发现。简而言之,CaSE 应启用人与机器之间的语义对齐,从而进一步改进交互式机器学习的基础。对 CaSE 进行了广泛的实验验证,通过生成可靠且有意义的解释来展示其有效性,这些解释的元素由上下文连贯的单词组成,因此适合以适当的方式更新人类心理模型。在定量分析过程中,建议的架构通过一致性属性和结果解释模型的局部保真度进行评估。据此,与 LIME 相比,CaSE 生成了更现实的解释模型,从而导致更高的局部保真度。


























 京公网安备 11010802027423号
京公网安备 11010802027423号