Image and Vision Computing ( IF 4.2 ) Pub Date : 2021-07-07 , DOI: 10.1016/j.imavis.2021.104246 Madhu Kiran 1 , Amran Bhuiyan 1 , Le Thanh Nguyen-Meidine 1 , Louis-Antoine Blais-Morin 2 , Ismail Ben Ayed 1 , Eric Granger 1
|
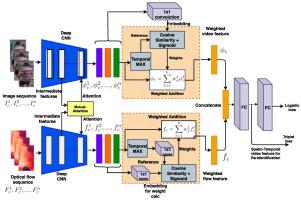
Person Re-Identification (ReID) is a challenging problem in many video analytics and surveillance applications, where a person's identity must be associated across a distributed non-overlapping network of cameras. Video-based person ReID has recently gained much interest given the potential for capturing discriminant spatio-temporal information from video clips that is unavailable for image-based ReID. Despite recent advances, deep learning (DL) models for video ReID often fail to leverage this information to improve the robustness of feature representations. In this paper, the motion pattern of a person is explored as an additional cue for ReID. In particular, a flow-guided Mutual Attention network is proposed for fusion of bounding box and optical flow sequences over tracklets using any 2D-CNN backbone, allowing to encode temporal information along with spatial appearance information. Our Mutual Attention network relies on the joint spatial attention between image and optical flow feature maps to activate a common set of salient features. In addition to flow-guided attention, we introduce a method to aggregate features from longer input streams for better video sequence-level representation. Our extensive experiments on three challenging video ReID datasets indicate that using the proposed approach allows to improve recognition accuracy considerably with respect to conventional gated-attention networks, and state-of-the-art methods for video-based person ReID.
中文翻译:
Flow 引导相互关注以实现行人重识别
人员重新识别 (ReID) 是许多视频分析和监控应用程序中的一个具有挑战性的问题,在这些应用程序中,一个人的身份必须在分布式非重叠摄像头网络中关联。鉴于从视频剪辑中捕获判别性时空信息的潜力,基于图像的人 ReID 最近引起了人们的极大兴趣,而这些信息对于基于图像的 ReID 来说是不可用的。尽管最近取得了进展,但视频 ReID 的深度学习 (DL) 模型通常无法利用这些信息来提高特征表示的鲁棒性。在本文中,将人的运动模式作为 ReID 的附加线索进行了探索。特别是,提出了一种流引导的相互注意网络,用于使用任何 2D-CNN 主干在轨迹上融合边界框和光流序列,允许将时间信息与空间外观信息一起编码。我们的相互注意网络依赖于图像和光流特征图之间的联合空间注意来激活一组共同的显着特征。除了流引导的注意力之外,我们还引入了一种方法来聚合来自较长输入流的特征,以获得更好的视频序列级表示。我们在三个具有挑战性的视频 ReID 数据集上进行的大量实验表明,相对于传统的门控注意力网络和基于视频的人员 ReID 的最先进方法,使用所提出的方法可以显着提高识别精度。我们的相互注意网络依赖于图像和光流特征图之间的联合空间注意来激活一组共同的显着特征。除了流引导的注意力之外,我们还引入了一种方法来聚合来自较长输入流的特征,以获得更好的视频序列级表示。我们在三个具有挑战性的视频 ReID 数据集上进行的大量实验表明,相对于传统的门控注意力网络和基于视频的人员 ReID 的最先进方法,使用所提出的方法可以显着提高识别精度。我们的相互注意网络依赖于图像和光流特征图之间的联合空间注意来激活一组共同的显着特征。除了流引导的注意力之外,我们还引入了一种方法来聚合来自较长输入流的特征,以获得更好的视频序列级表示。我们在三个具有挑战性的视频 ReID 数据集上进行的大量实验表明,相对于传统的门控注意力网络和基于视频的人员 ReID 的最先进方法,使用所提出的方法可以显着提高识别精度。










































 京公网安备 11010802027423号
京公网安备 11010802027423号