Science of the Total Environment ( IF 8 ) Pub Date : 2021-06-29 , DOI: 10.1016/j.scitotenv.2021.148738 Anuj Tiwari , Arun G. , Bramha Dutt Vishwakarma
|
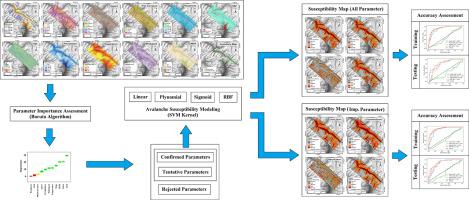
Due to ongoing climate change, water mass redistribution and related hazards are getting stronger and frequent. Therefore, predicting extreme hydrological events and related hazards is one of the highest priorities in geosciences. Machine Learning (ML) methods have shown promising prospects in this venture. Every ML method requires training where we know both the output (extreme event) and input (relevant physical parameters and variables). This step is critical to the efficacy of the ML method. The usual approach is to include a wide variety of hydro-meteorological observations and physical parameters, but recent advances in ML indicate that the efficacy of ML may not improve by increasing the number of input parameters. In fact, including unimportant parameters decreases the efficacy of ML algorithms. Therefore, it is imperative that the most relevant parameters are identified prior to training. In this study, we demonstrate this concept by predicting avalanche susceptibility in Leh-Manali highway (one of the most severely affected regions in India) with and without Parameter Importance Assessment (PIA). The avalanche locations were randomly divided into two groups: 70% for training and 30% for testing. Then, based on temporal and spatial sensor data, eleven avalanche influencing parameters were considered. The Boruta algorithm, an extension of Random Forest (RF) ML method that utilizes the importance measure to rank predictors, was used and it found nine out of eleven parameters to be important. Support Vector Machine (SVM) based ML technique is used for avalanche prediction, and to be comprehensive, four different kernel functions were employed (linear, polynomial, sigmoid, and radial basis function (RBF)). The prediction accuracy for linear, polynomial, sigmoid, and RBF kernels, with all the eleven parameters were found to be 80.4%, 81.7%, 39.2%, and 85.7%, respectively. While, when using selected parameters, the prediction accuracy for linear, polynomial, sigmoid, and RBF kernels were 84.1%, 86.6%, 43.0%, and 87.8%, respectively. We also identified locations where occurrences of avalanches are most likely. We conclude that parameter selection should be considered when applying ML methods in geosciences.
中文翻译:
参数重要性评估提高了机器学习方法在预测印度 Leh-Manali 高速公路雪崩地点的效率
由于持续的气候变化,水体重新分布和相关危害变得越来越强烈和频繁。因此,预测极端水文事件和相关灾害是地球科学的最高优先事项之一。机器学习 (ML) 方法在该项目中显示出广阔的前景。每个 ML 方法都需要训练,我们知道输出(极端事件)和输入(相关物理参数和变量)。此步骤对于 ML 方法的有效性至关重要。通常的方法是包括各种各样的水文气象观测和物理参数,但 ML 的最新进展表明,ML 的功效可能不会通过增加输入参数的数量来提高。事实上,包含不重要的参数会降低 ML 算法的效率。所以,必须在训练之前确定最相关的参数。在这项研究中,我们通过预测 Leh-Manali 高速公路(印度受影响最严重的地区之一)的雪崩敏感性来证明这一概念,无论是否使用参数重要性评估 (PIA)。雪崩位置随机分为两组:70% 用于训练,30% 用于测试。然后,基于时空传感器数据,考虑了十一个雪崩影响参数。Boruta 算法是随机森林 (RF) ML 方法的扩展,它利用重要性度量对预测变量进行排名,它发现 11 个参数中有 9 个是重要的。基于支持向量机 (SVM) 的 ML 技术用于雪崩预测,综合而言,采用了四种不同的核函数(线性、多项式、sigmoid 和径向基函数 (RBF))。线性、多项式、sigmoid 和 RBF 内核的预测准确率,所有 11 个参数分别为 80.4%、81.7%、39.2% 和 85.7%。而在使用选定参数时,线性、多项式、sigmoid 和 RBF 内核的预测精度分别为 84.1%、86.6%、43.0% 和 87.8%。我们还确定了最有可能发生雪崩的位置。我们得出结论,在地球科学中应用 ML 方法时应考虑参数选择。线性、多项式、sigmoid 和 RBF 核的预测精度分别为 84.1%、86.6%、43.0% 和 87.8%。我们还确定了最有可能发生雪崩的位置。我们得出结论,在地球科学中应用 ML 方法时应考虑参数选择。线性、多项式、sigmoid 和 RBF 核的预测精度分别为 84.1%、86.6%、43.0% 和 87.8%。我们还确定了最有可能发生雪崩的位置。我们得出结论,在地球科学中应用 ML 方法时应考虑参数选择。






















































 京公网安备 11010802027423号
京公网安备 11010802027423号