Signal Processing: Image Communication ( IF 3.5 ) Pub Date : 2021-06-07 , DOI: 10.1016/j.image.2021.116349 Sumanta Das , Ishita De Ghosh , Abir Chattopadhyay
|
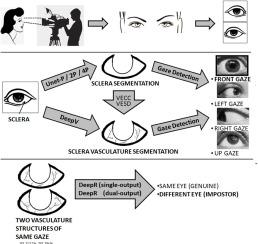
Sclera recognition is a promising ocular biometric modality because of contact-less, gaze-independent image acquisition in visible light. Moreover, it is unaffected even if the subjects are wearing contact lenses in eyes. However, it is a difficult task because several steps are required, each of which must be performed accurately and efficiently. In this work, sclera recognition is performed in the following steps, namely, segmentation of sclera region, extraction of sclera vasculature pattern, detection of gaze direction and finally comparison of two vasculature patterns for matching and recognition. The proposed segmentation model DSeg is based on well-known deep learning model UNet and reduces model complexity by creating a Knowledge Base of sclera and non-sclera colors. DSeg is a lightweight and environment-friendly model, which outperforms UNet in terms of speed, efficiency and accuracy. Two rule-based unsupervised vessel extraction methods require prior sclera segmentation and exhibit competing recognition performance to a supervised deep model for vessel extraction, which does not require prior sclera segmentation. A novel deep recognition model is proposed which compares two vessel structures taking into account their affine-transformation, and produces a single Boolean output to decide whether the structures match or not. The model does not require post logic in the matching process. The model is further improved to detect errors in prediction. We achieve best recognition rates with low false-acceptance-rates for two sets of training and validation, using the publicly available dataset SBVPI and the best achieved AUC score is 0.98.
中文翻译:
一种高效的深层巩膜识别框架,具有新颖的巩膜分割、血管提取和凝视检测
巩膜识别是一种很有前途的眼部生物识别方式,因为在可见光下进行非接触式、独立于注视的图像采集。此外,即使受试者的眼睛戴着隐形眼镜,它也不受影响。然而,这是一项艰巨的任务,因为需要几个步骤,每个步骤都必须准确有效地执行。在这项工作中,巩膜识别按照以下步骤进行,即巩膜区域的分割,巩膜血管模式的提取,视线方向的检测,最后比较两种血管模式进行匹配和识别。提出的分割模型 DSeg 基于众所周知的深度学习模型 UNet,通过创建巩膜和非巩膜颜色的知识库来降低模型复杂度。DSeg 是一个轻量级和环保的模型,它在速度、效率和准确性方面都优于 UNet。两种基于规则的无监督血管提取方法需要先行巩膜分割,并表现出与用于血管提取的监督深度模型的竞争识别性能,后者不需要先验巩膜分割。提出了一种新的深度识别模型,该模型在考虑仿射变换的情况下比较两个血管结构,并产生单个布尔输出来决定结构是否匹配。该模型在匹配过程中不需要后期逻辑。该模型进一步改进以检测预测中的错误。我们使用公开可用的数据集 SBVPI,在两组训练和验证中以较低的错误接受率获得了最佳识别率,并且获得的最佳 AUC 分数为 0.98。效率和准确性。两种基于规则的无监督血管提取方法需要先行巩膜分割,并表现出与用于血管提取的监督深度模型的竞争识别性能,后者不需要先验巩膜分割。提出了一种新的深度识别模型,该模型在考虑仿射变换的情况下比较两个血管结构,并产生单个布尔输出来决定结构是否匹配。该模型在匹配过程中不需要后期逻辑。该模型进一步改进以检测预测中的错误。我们使用公开可用的数据集 SBVPI,在两组训练和验证中以较低的错误接受率获得了最佳识别率,并且获得的最佳 AUC 分数为 0.98。效率和准确性。两种基于规则的无监督血管提取方法需要先行巩膜分割,并表现出与用于血管提取的监督深度模型的竞争识别性能,后者不需要先验巩膜分割。提出了一种新的深度识别模型,该模型在考虑仿射变换的情况下比较两个血管结构,并产生单个布尔输出来决定结构是否匹配。该模型在匹配过程中不需要后期逻辑。该模型进一步改进以检测预测中的错误。我们使用公开可用的数据集 SBVPI,在两组训练和验证中以较低的错误接受率获得了最佳识别率,并且获得的最佳 AUC 分数为 0.98。两种基于规则的无监督血管提取方法需要先行巩膜分割,并表现出与用于血管提取的监督深度模型的竞争识别性能,后者不需要先验巩膜分割。提出了一种新的深度识别模型,该模型在考虑仿射变换的情况下比较两个血管结构,并产生单个布尔输出来决定结构是否匹配。该模型在匹配过程中不需要后期逻辑。该模型进一步改进以检测预测中的错误。我们使用公开可用的数据集 SBVPI,在两组训练和验证中以较低的错误接受率获得了最佳识别率,并且获得的最佳 AUC 分数为 0.98。两种基于规则的无监督血管提取方法需要先行巩膜分割,并表现出与用于血管提取的监督深度模型的竞争识别性能,后者不需要先验巩膜分割。提出了一种新的深度识别模型,该模型在考虑仿射变换的情况下比较两个血管结构,并产生单个布尔输出来决定结构是否匹配。该模型在匹配过程中不需要后期逻辑。该模型进一步改进以检测预测中的错误。我们使用公开可用的数据集 SBVPI,在两组训练和验证中以较低的错误接受率获得了最佳识别率,并且获得的最佳 AUC 分数为 0.98。


























 京公网安备 11010802027423号
京公网安备 11010802027423号