Engineering Science and Technology, an International Journal ( IF 5.1 ) Pub Date : 2021-06-04 , DOI: 10.1016/j.jestch.2021.05.015 Deepti Sisodia , Dilip Singh Sisodia
|
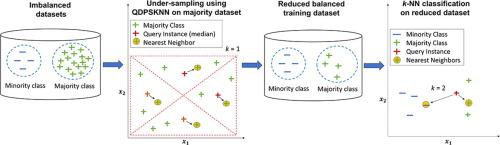
In online advertising, the user-clicks dataset based fraudulent publishers’ classification models exhibit poor performance due to high skewness in class distribution of the publishers. The nearest-neighbor based classification techniques are popularly used to reduce the impact of class skewness on performance. The Nearest-Neighbor techniques use Prototype Selection (PS) methods to select promising samples before classifying them for reducing the size of training data. Although Nearest-Neighbor techniques are simple to use and reduce the negative impact of the loss of potential information, they suffer from higher storage requirements and slower classification speed when applied on datasets with skewed class distributions. In this paper, we propose a Quad Division Prototype Selection-based k-Nearest Neighbor classifier (QDPSKNN) by introducing quad division method for handling uneven class distribution. The quad-division divides the data into four quartiles (groups) and performs controlled under-sampling for balancing class distribution. It reduces the size of the training dataset by selecting only the relevant prototypes in the form of nearest-neighbors. The performance of QDPSKNN is evaluated on Fraud Detection in Mobile Advertising (FDMA) user-click dataset and fifteen other benchmark imbalanced datasets to test its generalizing behaviour. The performance is also compared with one baseline model (k-NN) and four other prototype selection methods such as NearMiss-1, NearMiss-2, NearMiss-3, and Condensed Nearest-Neighbor. The results show improved classification performance with QDPSKNN in terms of precision, recall, f-measure, g-mean, reduction rate and execution time, compared to existing prototype selection methods in the classification of fraudulent publishers as well as on other benchmark imbalanced datasets. Wilcoxon signed ranked test is conducted to demonstrate significant differences amid QDPSKNN and state-of-the-art methods.
中文翻译:
基于四分法原型选择的 k 最近邻分类器,用于从高度偏斜的用户点击数据集中检测点击欺诈
在在线广告中,基于用户点击数据集的欺诈发布者的分类模型由于发布者类别分布的高偏度而表现出较差的性能。基于最近邻的分类技术被广泛用于减少类偏度对性能的影响。最近邻技术使用原型选择 (PS) 方法来选择有希望的样本,然后对它们进行分类以减少训练数据的大小。尽管最近邻技术使用简单并减少了潜在信息丢失的负面影响,但当应用于具有偏态类分布的数据集时,它们会遭受更高的存储要求和更慢的分类速度。在本文中,我们通过引入四分法来处理不均匀的类分布,提出了一种基于四分法原型选择的 k-最近邻分类器(QDPSKNN)。四分法将数据分成四个四分位数(组)并执行受控欠采样以平衡类分布。它通过仅选择最近邻形式的相关原型来减少训练数据集的大小。QDPSKNN 的性能在移动广告欺诈检测 (FDMA) 用户点击数据集和其他 15 个基准不平衡数据集上进行评估,以测试其泛化行为。该性能还与一个基线模型 (k-NN) 和其他四种原型选择方法(例如 NearMiss-1、NearMiss-2、NearMiss-3 和 Condensed Nearest-Neighbor)进行了比较。结果表明,与欺诈发布者分类以及其他基准不平衡数据集的现有原型选择方法相比,QDPSKNN 在精度、召回率、f 度量、g 均值、减少率和执行时间方面提高了分类性能。进行 Wilcoxon 符号排序测试以证明 QDPSKNN 和最先进方法之间的显着差异。










































 京公网安备 11010802027423号
京公网安备 11010802027423号