Current Bioinformatics ( IF 2.4 ) Pub Date : 2021-02-28 , DOI: 10.2174/1574893615999200707141420 Pratik Joshi 1 , V Masilamani 1 , Raj Ramesh 2
|
Background: Preventing adverse drug reactions (ADRs) is imperative for the safety of the people. The problem of under-reporting the ADRs has been prevalent across the world, making it difficult to develop the prediction models, which are unbiased. As a result, most of the models are skewed to the negative samples leading to high accuracy but poor performance in other metrics such as precision, recall, F1 score, and AUROC score.
Objective: In this work, we have proposed a novel way of predicting the ADRs by balancing the dataset.
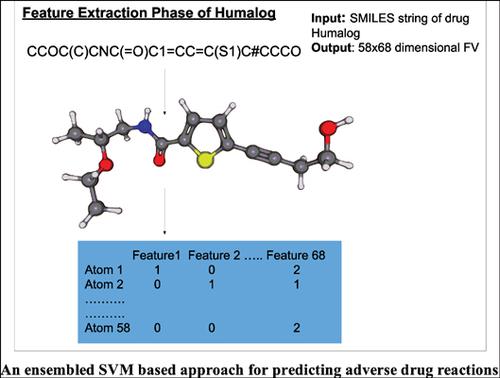
Methods: The whole data set has been partitioned into balanced smaller data sets. SVMs with optimal kernel have been learned using each of the balanced data sets and the prediction of given ADR for the given drug has been obtained by voting from the ensembled optimal SVMs learned.
Results: We have found that results are encouraging and comparable with the competing methods in the literature and obtained the average sensitivity of 0.97 for all the ADRs. The model has been interpreted and explained with SHAP values by various plots.
Conclusion: A novel way of predicting ADRs by balancing the dataset has been proposed thereby reducing the effect of unbalanced datasets.
中文翻译:
基于组合SVM的药物不良反应预测方法
背景:预防药物不良反应(ADR)对于人们的安全至关重要。报告不足的ADR问题已在世界各地普遍存在,这使得很难开发无偏见的预测模型。结果,大多数模型都偏向于负样本,从而导致准确性较高,但在其他指标(例如精度,召回率,F1得分和AUROC得分)方面却表现不佳。
目的:在这项工作中,我们提出了一种通过平衡数据集来预测ADR的新颖方法。
方法:整个数据集已被划分为平衡的较小数据集。已经使用每个平衡数据集学习了具有最佳内核的SVM,并且通过从学习的整体最优SVM中投票获得了给定药物的给定ADR预测。
结果:我们发现结果令人鼓舞,并且与文献中的竞争方法相当,并且所有ADR的平均灵敏度均为0.97。该模型已通过各种绘图使用SHAP值进行了解释和说明。
结论:提出了一种通过平衡数据集来预测ADR的新方法,从而减少了不平衡数据集的影响。










































 京公网安备 11010802027423号
京公网安备 11010802027423号