Chinese Journal of Analytical Chemistry ( IF 1.2 ) Pub Date : 2021-05-12 , DOI: 10.1016/s1872-2040(21)60102-0 Jing-Jing SUN , Wu-De YANG , Mei-Chen FENG , Lu-Jie XIAO , Hui SUN , Muhammad-Saleem KUBAR
|
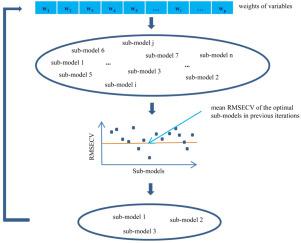
With the generation of high-dimensional data from spectroscopic instruments, the role of variable selection in spectral modeling has become very important. This research proposes a new variable selection algorithm, named adaptive variable re-weighting and shrinking approach (AVRSA), based on model population analysis (MPA) and weighted bootstrap sampling (WBS). In this algorithm, WBS is used to generate sub-datasets for modeling in each iteration round, and the variable weight and space are updated by statistically evaluating the optimal sub-models. Unlike most other variable selection methods, the average prediction performance of the optimal sub-models by AVRSA must be preferable to that of the previous iteration. The best informative variables are obtained until no further optimal sub-models are generated. This method is checked on three near infrared (NIR) datasets. Three variable selection methods, including competitive adaptive reweighted sampling (CARS), MonteCarlo uninformative variable elimination (MC-UVE) and iteratively variable subset optimization (IVSO), are used for comparison. Compared with these variable selection algorithms, AVRSA selects the least informative variables, which is convenient for the development of portable instruments. Compared with the full-spectrum PLS model, the root mean square error of the validation set (RMSEP) of corn starch is decreased from 0.2614 to 0.1093, and the RMSEP of corn protein is decreased from 0.0977 to 0.0374. In addition, the RMSEP of the wheat dataset is decreased from 0.2585 to 0.2157, and the RMSEP of the wheat kernel dataset is decreased from 0.7816 to 0.6661. The results show that the proposed method is very efficient for the high-dimensional spectrum to find the best variables and improve the model's prediction performance.
中文翻译:
近红外光谱多变量校正中变量选择的自适应变量重加权和收缩方法
随着光谱仪器生成高维数据,变量选择在光谱建模中的作用变得非常重要。这项研究基于模型总体分析(MPA)和加权自举抽样(WBS),提出了一种新的变量选择算法,称为自适应变量重新加权和收缩方法(AVRSA)。在该算法中,WBS用于生成子数据集以在每个迭代回合中进行建模,并且通过统计评估最佳子模型来更新可变权重和空间。与大多数其他变量选择方法不同,AVRSA最优子模型的平均预测性能必须优于之前的迭代。获得最佳的信息变量,直到没有进一步的最佳子模型生成为止。在三个近红外(NIR)数据集上检查了此方法。比较了三种变量选择方法,包括竞争性自适应加权抽样(CARS),蒙特卡洛非信息变量消除(MC-UVE)和迭代变量子集优化(IVSO)。与这些变量选择算法相比,AVRSA选择信息最少的变量,这为便携式仪器的开发提供了方便。与全光谱PLS模型相比,玉米淀粉验证集(RMSEP)的均方根误差从0.2614降低至0.1093,玉米蛋白的RMSEP从0.0977降低至0.0374。此外,小麦数据集的RMSEP从0.2585降低到0.2157,小麦仁数据集的RMSEP从0.7816降低到0.6661。


























 京公网安备 11010802027423号
京公网安备 11010802027423号