Journal of Manufacturing Systems ( IF 12.2 ) Pub Date : 2021-05-11 , DOI: 10.1016/j.jmsy.2021.05.001 Andrea de Giorgio , Antonio Maffei , Mauro Onori , Lihui Wang
|
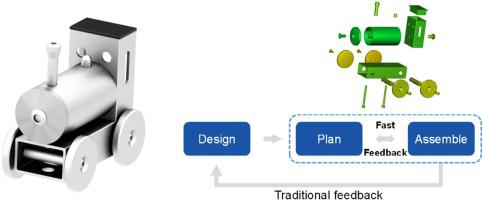
Literature shows that reinforcement learning (RL) and the well-known optimization algorithms derived from it have been applied to assembly sequence planning (ASP); however, the way this is done, as an offline process, ends up generating optimization methods that are not exploiting the full potential of RL. Today’s assembly lines need to be adaptive to changes, resilient to errors and attentive to the operators’ skills and needs. If all of these aspects need to evolve towards a new paradigm, called Industry 4.0, the way RL is applied to ASP needs to change as well: the RL phase has to be part of the assembly execution phase and be optimized with time and several repetitions of the process. This article presents an agile exploratory experiment in ASP to prove the effectiveness of RL techniques to execute ASP as an adaptive, online and experience-driven optimization process, directly at assembly time. The human-assembly interaction is modelled through the input-outputs of an assembly guidance system built as an assembly digital twin. Experimental assemblies are executed without pre-established assembly sequence plans and adapted to the operators’ needs. The experiments show that precedence and transition matrices for an assembly can be generated from the statistical knowledge of several different assembly executions. When the frequency of a given subassembly reinforces its importance, statistical results obtained from the experiments prove that online RL applications are not only possible but also effective for learning, teaching, executing and improving assembly tasks at the same time. This article paves the way towards the application of online RL algorithms to ASP.
中文翻译:
通过工业4.0自适应制造的交互式指导系统实现在线在线学习装配顺序计划
文献表明,强化学习(RL)及其衍生的众所周知的优化算法已应用于装配顺序计划(ASP)。但是,作为脱机过程的完成方式最终会生成无法充分利用RL潜力的优化方法。当今的装配线需要适应变化,对错误有弹性,并注意操作员的技能和需求。如果所有这些方面都需要朝着称为工业4.0的新范例发展,那么将RL应用于ASP的方式也需要改变:RL阶段必须是装配执行阶段的一部分,并且要随着时间和多次重复进行优化。的过程。本文介绍了一种在ASP中进行的敏捷探索性实验,以证明RL技术将ASP作为自适应方法执行的有效性,在线和由经验驱动的优化过程,直接在组装时进行。人与装配的交互作用是通过装配指导数字系统构建的装配指导系统的输入输出进行建模的。在没有预先建立的装配顺序计划的情况下执行实验装配,并适应操作员的需求。实验表明,程序集的优先级和转换矩阵可以从几种不同程序集执行的统计知识中生成。当给定组件的频率增强其重要性时,从实验中获得的统计结果证明,在线RL应用程序不仅可能,而且对于学习,教学,执行和改进装配任务同时有效。本文为将在线RL算法应用于ASP铺平了道路。










































 京公网安备 11010802027423号
京公网安备 11010802027423号