Computers & Graphics ( IF 2.5 ) Pub Date : 2021-04-30 , DOI: 10.1016/j.cag.2021.04.013 Jun-Xiong Cai , Tai-Jiang Mu , Yu-Kun Lai , Shi-Min Hu
|
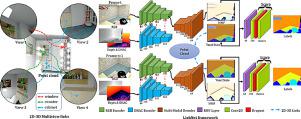
This paper proposes LinkNet, a 2D-3D linked multi-modal network served for online semantic segmentation of RGB-D videos, which is essential for real-time applications such as robot navigation. Existing methods for RGB-D semantic segmentation usually work in the regular image domain, which allows efficient processing using convolutional neural networks (CNNs). However, RGB-D videos are captured from a 3D scene, and different frames can contain useful information of the same local region from different views. Working solely in the image domain fails to utilize such crucial information. Our novel approach is based on joint 2D and 3D analysis. The online process is realized simultaneously with 3D scene reconstruction, from which we set up 2D-3D links between continuous RGB-D frames and 3D point cloud. We combine image color and view-insensitive geometric features generated from the 3D point cloud for multi-modal semantic feature learning. Our LinkNet further uses a recurrent neural network (RNN) module to dynamically maintain the hidden semantic states during 3D fusion, and refines the voxel-based labeling results. The experimental results on SceneNet [1] and ScanNet [2] demonstrate that the semantic segmentation results of our framework are stable and effective.
中文翻译:
LinkNet:用于RGB-D视频在线语义分割的2D-3D链接多模式网络
本文提出了LinkNet,这是一种2D-3D链接的多模式网络,可用于RGB-D视频的在线语义分割,这对于实时应用(例如机器人导航)必不可少。现有的RGB-D语义分割方法通常在常规图像域中工作,从而可以使用卷积神经网络(CNN)进行有效处理。但是,RGB-D视频是从3D场景捕获的,并且不同的帧可以包含来自不同视图的相同局部区域的有用信息。仅在图像域中工作无法利用这些关键信息。我们的新颖方法基于2D和3D联合分析。在线过程与3D场景重建同时实现,由此我们在连续的RGB-D帧和3D点云之间建立2D-3D链接。我们将图像颜色和从3D点云生成的对视图不敏感的几何特征结合起来,以进行多模式语义特征学习。我们的LinkNet进一步使用循环神经网络(RNN)模块在3D融合过程中动态维护隐藏的语义状态,并完善基于体素的标记结果。在SceneNet [1]和ScanNet [2]上的实验结果表明,我们框架的语义分割结果是稳定且有效的。








































 京公网安备 11010802027423号
京公网安备 11010802027423号