当前位置:
X-MOL 学术
›
Steel Res. Int.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Prediction and Explanation Models for Hot Metal Temperature, Silicon Concentration, and Cooling Capacity in Ironmaking Blast Furnaces
Steel Research International ( IF 2.2 ) Pub Date : 2021-04-22 , DOI: 10.1002/srin.202100078 Edwin Lughofer 1 , Robert Pollak 1 , Christoph Feilmayr 2 , Magdalena Schatzl 3 , Susanne Saminger-Platz 1
Steel Research International ( IF 2.2 ) Pub Date : 2021-04-22 , DOI: 10.1002/srin.202100078 Edwin Lughofer 1 , Robert Pollak 1 , Christoph Feilmayr 2 , Magdalena Schatzl 3 , Susanne Saminger-Platz 1
Affiliation
|
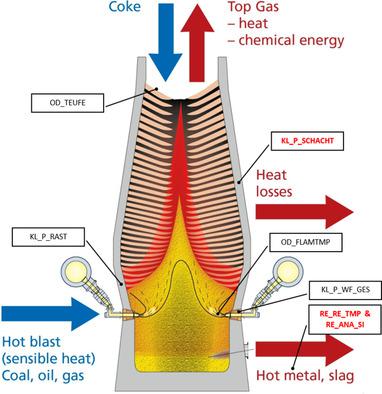
Herein, the establishment of data-driven prediction and explanation models for three essential process variables in ironmaking blast furnace processes, namely hot metal temperature, silicon concentration, and cooling capacity is demonstrated. Aside a reliable prediction quality of the models with sufficient prediction horizon, an additional main goal has been to establish interpretable and revealing models. To support (linguistic) interpretability, the main focus has been set on the extraction of rule-based models from a large database collected at a particular blast furnace process located at the partner company's site. Due to expected uncertainty in the data, due to, e.g., measurement noise, fuzzy systems are an adequate architectural choice for achieving models in a robust rule-based form. For a fully automatic training of the predictive fuzzy systems new feature ranking methods have been performed on the one side and a special granular rule extraction procedure on the other side. Testing the obtained models on two separate test datasets from consecutive years shows a stable prediction performance without any error drifts and a higher performance than other related machine learning methods including deep neural networks, and others. Moreover, the final models, turned out to have maximal 4–5 inputs and just a couple of rules and allowed to gain new insights into the processes.
中文翻译:

炼铁高炉铁水温度、硅浓度和冷量预测解释模型
在此,论证了对炼铁高炉过程中三个基本过程变量(即铁水温度、硅浓度和冷却能力)的数据驱动预测和解释模型的建立。除了具有足够预测范围的模型的可靠预测质量之外,另一个主要目标是建立可解释和具有启发性的模型。为了支持(语言)可解释性,主要关注点是从位于合作伙伴公司现场的特定高炉工艺收集的大型数据库中提取基于规则的模型。由于数据中的预期不确定性,例如由于测量噪声,模糊系统是实现基于规则形式的稳健模型的适当架构选择。对于预测模糊系统的全自动训练,一方面执行了新的特征排序方法,另一方面执行了特殊的粒度规则提取程序。在连续几年的两个独立测试数据集上测试获得的模型显示出稳定的预测性能,没有任何误差漂移,并且比其他相关机器学习方法(包括深度神经网络等)具有更高的性能。此外,最终的模型结果证明最多有 4-5 个输入和几个规则,并允许获得对过程的新见解。在连续几年的两个独立测试数据集上测试获得的模型显示出稳定的预测性能,没有任何误差漂移,并且比其他相关机器学习方法(包括深度神经网络等)具有更高的性能。此外,最终的模型结果证明最多有 4-5 个输入和几个规则,并允许获得对过程的新见解。在连续几年的两个独立测试数据集上测试获得的模型显示出稳定的预测性能,没有任何误差漂移,并且比其他相关机器学习方法(包括深度神经网络等)具有更高的性能。此外,最终的模型结果证明最多有 4-5 个输入和几个规则,并允许获得对过程的新见解。
更新日期:2021-04-22
中文翻译:
炼铁高炉铁水温度、硅浓度和冷量预测解释模型
在此,论证了对炼铁高炉过程中三个基本过程变量(即铁水温度、硅浓度和冷却能力)的数据驱动预测和解释模型的建立。除了具有足够预测范围的模型的可靠预测质量之外,另一个主要目标是建立可解释和具有启发性的模型。为了支持(语言)可解释性,主要关注点是从位于合作伙伴公司现场的特定高炉工艺收集的大型数据库中提取基于规则的模型。由于数据中的预期不确定性,例如由于测量噪声,模糊系统是实现基于规则形式的稳健模型的适当架构选择。对于预测模糊系统的全自动训练,一方面执行了新的特征排序方法,另一方面执行了特殊的粒度规则提取程序。在连续几年的两个独立测试数据集上测试获得的模型显示出稳定的预测性能,没有任何误差漂移,并且比其他相关机器学习方法(包括深度神经网络等)具有更高的性能。此外,最终的模型结果证明最多有 4-5 个输入和几个规则,并允许获得对过程的新见解。在连续几年的两个独立测试数据集上测试获得的模型显示出稳定的预测性能,没有任何误差漂移,并且比其他相关机器学习方法(包括深度神经网络等)具有更高的性能。此外,最终的模型结果证明最多有 4-5 个输入和几个规则,并允许获得对过程的新见解。在连续几年的两个独立测试数据集上测试获得的模型显示出稳定的预测性能,没有任何误差漂移,并且比其他相关机器学习方法(包括深度神经网络等)具有更高的性能。此外,最终的模型结果证明最多有 4-5 个输入和几个规则,并允许获得对过程的新见解。


























 京公网安备 11010802027423号
京公网安备 11010802027423号