Gondwana Research ( IF 7.2 ) Pub Date : 2021-04-20 , DOI: 10.1016/j.gr.2021.03.015 Yang Wang , Shiqing Cheng , Fengbo Zhang , Naichao Feng , Lei Li , Xinzhe Shen , Juhua Li , Haiyang Yu
|
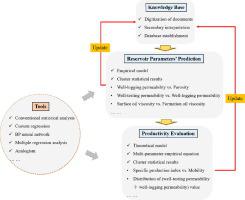
The upstream oil and gas industry has been struggling with massive data files for decades. These monolithic files are supposed to be a valuable asset for companies, but in reality they are generally underutilized or even discarded. In this paper, we present the application of big data technique in the oil fields of western South China sea to predict the reservoir parameters and evaluate well productivity. The data files are firstly classified and stored by clustering analysis method on the basis of different labels. Combining different analysis tools, the variation law and correlations between different parameters are studied, and the knowledge base is thus established. We analyze the distribution laws of formation and fluid parameters, calculate the relationship between different parameters, and adopt the theoretical/empirical formula methods, to minimize the uncertainties of prediction results. After that, the oil productivities are comprehensively evaluated by clustering analysis and grey correlation methods. The productivity charts are built for all datasets and the classification rule according to sedimentary facies, reservoir member and formation oil state. Based on the clustering results, we analyze the key factors that impact oil production rate, and obtain the multi-parameter empirical productivity equations to evaluate well productivity. Finally, we establish the real-time-update software platform that integrates knowledge base, job management, parameter prediction, test design, interpretation, etc. Compared with the current methods of parameters’ prediction and productivity evaluation which need extensive experiment work or plenty of known input parameters, we integrate all available data sets and different approaches by big data technique to address the key uncertainties rather analyze each data source individually.
中文翻译:
大数据技术在储层参数预测和产能评价中的应用:以南海西部为例
上游石油和天然气行业数十年来一直在处理海量数据文件。这些整体文件对于公司而言是宝贵的资产,但实际上,它们通常未被充分利用,甚至被丢弃。本文介绍了大数据技术在南海西部油田中的应用,以预测储层参数并评价油井产能。首先通过聚类分析的方法,根据不同的标签对数据文件进行分类和存储。结合不同的分析工具,研究了不同参数之间的变化规律和相关性,从而建立了知识库。我们分析地层和流体参数的分布规律,计算不同参数之间的关系,并采用理论/经验公式方法,最大限度地减少预测结果的不确定性。之后,通过聚类分析和灰色关联法对石油生产率进行综合评估。根据沉积相,储层成员和地层油状态为所有数据集和分类规则建立了生产率图表。基于聚类结果,我们分析了影响产油率的关键因素,并获得了多参数经验生产率方程式来评价油井生产率。最后,我们建立了一个实时更新的软件平台,该平台集成了知识库,作业管理,参数预测,测试设计,解释等功能。与目前的参数预测和生产率评估方法相比,该方法需要大量的实验工作或大量的工作。已知的输入参数,










































 京公网安备 11010802027423号
京公网安备 11010802027423号