当前位置:
X-MOL 学术
›
J. Softw. Evol. Process
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
On the value of filter feature selection techniques in homogeneous ensembles effort estimation
Journal of Software: Evolution and Process ( IF 1.7 ) Pub Date : 2021-03-30 , DOI: 10.1002/smr.2343 Mohamed Hosni 1, 2 , Ali Idri 1 , Alain Abran 3
Journal of Software: Evolution and Process ( IF 1.7 ) Pub Date : 2021-03-30 , DOI: 10.1002/smr.2343 Mohamed Hosni 1, 2 , Ali Idri 1 , Alain Abran 3
Affiliation
|
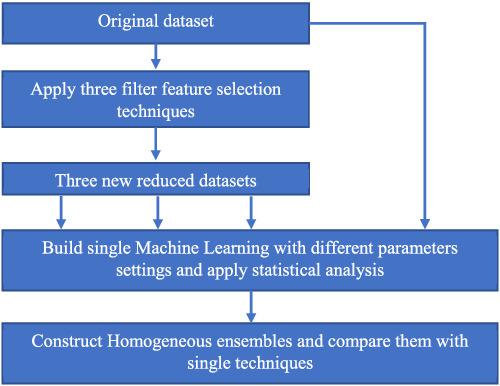
Software development effort estimation (SDEE) remains as the principal activity in software project management planning. Over the past four decades, several methods have been proposed to estimate the effort required to develop a software system, including more recently machine learning (ML) techniques. Because ML performance accuracy depends on the features that feed the ML technique, selecting the appropriate features in the preprocessing data step is important. This paper investigates three filter feature selection techniques to check the predictive capability of four single ML techniques: K-nearest neighbor, support vector regression, multilayer perceptron, and decision trees and their homogeneous ensembles over six well-known datasets. Furthermore, the single and ensembles techniques were optimized using the grid search optimization method. The results suggest that the three filter feature selection techniques investigated improve the reasonability and the accuracy performance of the four single techniques. Moreover, the homogeneous ensembles are statistically more accurate than the single techniques. Finally, adopting a random process (i.e., random subspace method) to select the inputs feature for ML technique is not always effective to generate an accurate homogeneous ensemble.
中文翻译:

关于滤波器特征选择技术在同构集成努力估计中的价值
软件开发工作量估算 (SDEE) 仍然是软件项目管理计划中的主要活动。在过去的四年中,已经提出了几种方法来估计开发软件系统所需的工作量,包括最近的机器学习 (ML) 技术。由于 ML 性能准确性取决于提供给 ML 技术的特征,因此在预处理数据步骤中选择合适的特征很重要。本文研究了三种过滤器特征选择技术,以检查四种单一 ML 技术的预测能力:K-最近邻、支持向量回归、多层感知器和决策树以及它们在六个众所周知的数据集上的同构集成。此外,使用网格搜索优化方法优化了单个和集成技术。结果表明,研究的三种滤波器特征选择技术提高了四种单一技术的合理性和准确性。此外,同质集成在统计上比单一技术更准确。最后,采用随机过程(即随机子空间方法)来选择 ML 技术的输入特征对于生成准确的同构集成并不总是有效。
更新日期:2021-06-02
中文翻译:
关于滤波器特征选择技术在同构集成努力估计中的价值
软件开发工作量估算 (SDEE) 仍然是软件项目管理计划中的主要活动。在过去的四年中,已经提出了几种方法来估计开发软件系统所需的工作量,包括最近的机器学习 (ML) 技术。由于 ML 性能准确性取决于提供给 ML 技术的特征,因此在预处理数据步骤中选择合适的特征很重要。本文研究了三种过滤器特征选择技术,以检查四种单一 ML 技术的预测能力:K-最近邻、支持向量回归、多层感知器和决策树以及它们在六个众所周知的数据集上的同构集成。此外,使用网格搜索优化方法优化了单个和集成技术。结果表明,研究的三种滤波器特征选择技术提高了四种单一技术的合理性和准确性。此外,同质集成在统计上比单一技术更准确。最后,采用随机过程(即随机子空间方法)来选择 ML 技术的输入特征对于生成准确的同构集成并不总是有效。










































 京公网安备 11010802027423号
京公网安备 11010802027423号