Computers & Electrical Engineering ( IF 4.0 ) Pub Date : 2021-03-25 , DOI: 10.1016/j.compeleceng.2021.107117 Federico A. Galatolo , Mario G.C.A. Cimino , Gigliola Vaglini
|
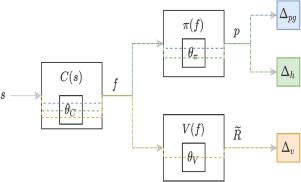
In this research, some of the issues that arise from the scalarization of the multi-objective optimization problem in the Advantage Actor–Critic (A2C) reinforcement learning algorithm are investigated. The paper shows how a naive scalarization can lead to gradients overlapping. Furthermore, the possibility that the entropy regularization term can be a source of uncontrolled noise is discussed. With respect to the above issues, a technique to avoid gradient overlapping is proposed, while keeping the same loss formulation. Moreover, a method to avoid the uncontrolled noise, by sampling the actions from distributions with a desired minimum entropy, is investigated. Pilot experiments have been carried out to show how the proposed method speeds up the training. The proposed approach can be applied to any Advantage-based Reinforcement Learning algorithm.
中文翻译:
解决基于优势的强化学习算法的标量化问题
在这项研究中,研究了在“优势行动者—批判”(A2C)强化学习算法中,由多目标优化问题的规模化引起的一些问题。本文展示了朴素的标量化如何导致梯度重叠。此外,讨论了熵正则项可以成为不受控制的噪声源的可能性。针对上述问题,提出了一种在保持相同损耗公式的同时避免梯度重叠的技术。此外,研究了一种通过从具有期望的最小熵的分布中采样动作来避免不受控制的噪声的方法。已经进行了试验实验,以显示所提出的方法如何加快训练速度。所提出的方法可以应用于任何基于优势的强化学习算法。










































 京公网安备 11010802027423号
京公网安备 11010802027423号