Pattern Recognition Letters ( IF 3.9 ) Pub Date : 2021-03-21 , DOI: 10.1016/j.patrec.2021.03.013 Abhimanyu Sahu , Ananda S. Chowdhury
|
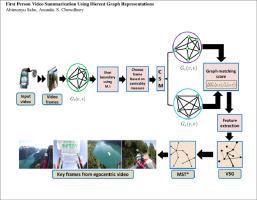
First-person video summarization has emerged as an important research problem for computer vision and multimedia communities. In this paper, we show how different graph representations can be developed for accurately summarizing first-person (egocentric) videos in a computationally efficient manner. Each frame in a video is first represented as a weighted graph. A shot boundary detection method using graph based mutual information is developed. We next construct a weighted graph for each shot. A representative frame from each shot is selected using a graph centrality measure. A new way of characterizing egocentric video frames using a graph based center-surround model is shown next. Here, each representative frame is modeled as a union of a center region (graph) and a surround region (graph). By exploiting spectral measures of dissimilarity between the two (center and surround) graphs, optimal center and surround regions are determined. Optimal regions for all frames within a shot are kept the same as that of the representative frame. Center-surround differences in entropy and optical flow values along with PHOG (Pyramidal HOG) features are extracted from each frame. All frames in a video are finally represented by another weighted graph, termed as a Video Similarity Graph (VSG). The frames are clustered by applying a Minimum Spanning Tree (MST) based approach with a new measure for inadmissible edges. Frames closest to the centroid of each cluster are captured to build the summary. Experimental evaluation on two benchmark datasets indicate the advantage of the proposed formulation.
中文翻译:
使用不同图形表示的第一人称视频摘要
第一人称视频摘要已成为计算机视觉和多媒体社区的重要研究问题。在本文中,我们展示了如何开发不同的图形表示形式,以便以计算有效的方式准确总结第一人称(以自我为中心)视频。视频中的每个帧首先表示为加权图。开发了一种基于图的互信息的镜头边界检测方法。接下来,我们为每个镜头构造一个加权图。使用图形中心度测量从每个镜头中选择一个代表帧。接下来显示使用基于图的中心环绕模型表征以自我为中心的视频帧的新方法。在此,将每个代表性框架建模为中心区域(图形)和周围区域(图形)的并集。通过利用两个图(中心图和周围图)之间不相似的频谱度量,可以确定最佳的中心图和周围图区域。镜头中所有帧的最佳区域应保持与代表帧的最佳区域相同。从每个帧中提取熵和光流值的中心周围差异以及PHOG(金字塔形HOG)特征。视频中的所有帧最终都由另一个加权图表示,称为视频相似度图(VSG)。通过应用基于最小生成树(MST)的方法对帧进行聚类,并采用了针对不可接受边缘的新度量。捕获最接近每个聚类质心的帧以构建摘要。对两个基准数据集的实验评估表明了所提出配方的优势。确定最佳的中心和周围区域。镜头中所有帧的最佳区域应保持与代表帧的最佳区域相同。从每个帧中提取熵和光流值的中心周围差异以及PHOG(金字塔形HOG)特征。视频中的所有帧最终都由另一个加权图表示,称为视频相似度图(VSG)。通过应用基于最小生成树(MST)的方法对帧进行聚类,并采用了针对不可接受边缘的新度量。捕获最接近每个聚类质心的帧以构建摘要。对两个基准数据集的实验评估表明了所提出配方的优势。确定最佳的中心和周围区域。镜头中所有帧的最佳区域应保持与代表帧的最佳区域相同。从每个帧中提取熵和光流值的中心周围差异以及PHOG(金字塔形HOG)特征。视频中的所有帧最终都由另一个加权图表示,称为视频相似度图(VSG)。通过应用基于最小生成树(MST)的方法对帧进行聚类,并采用了针对不可接受边缘的新度量。捕获最接近每个聚类质心的帧以构建摘要。对两个基准数据集的实验评估表明了所提出配方的优势。从每个帧中提取熵和光流值的中心周围差异以及PHOG(金字塔形HOG)特征。视频中的所有帧最终都由另一个加权图表示,称为视频相似度图(VSG)。通过应用基于最小生成树(MST)的方法对帧进行聚类,并采用了针对不可接受边缘的新度量。捕获最接近每个聚类质心的帧以构建摘要。对两个基准数据集的实验评估表明了所提出配方的优势。从每个帧中提取熵和光流值的中心周围差异以及PHOG(金字塔形HOG)特征。视频中的所有帧最终都由另一个加权图表示,称为视频相似度图(VSG)。通过应用基于最小生成树(MST)的方法对帧进行聚类,并采用了针对不可接受边缘的新度量。捕获最接近每个聚类质心的帧以构建摘要。对两个基准数据集的实验评估表明了所提出配方的优势。通过应用基于最小生成树(MST)的方法对帧进行聚类,并采用了针对不可接受边缘的新度量。捕获最接近每个聚类质心的帧以构建摘要。对两个基准数据集的实验评估表明了所提出配方的优势。通过应用基于最小生成树(MST)的方法对帧进行聚类,并采用了针对不可接受边缘的新度量。捕获最接近每个聚类质心的帧以构建摘要。对两个基准数据集的实验评估表明了所提出配方的优势。










































 京公网安备 11010802027423号
京公网安备 11010802027423号