当前位置:
X-MOL 学术
›
Geosci. Data J.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
A real-world dataset and data simulation algorithm for automated fish species identification
Geoscience Data Journal ( IF 3.3 ) Pub Date : 2021-03-18 , DOI: 10.1002/gdj3.114 Vaneeda Allken 1 , Shale Rosen 1 , Nils Olav Handegard 1 , Ketil Malde 1, 2
Geoscience Data Journal ( IF 3.3 ) Pub Date : 2021-03-18 , DOI: 10.1002/gdj3.114 Vaneeda Allken 1 , Shale Rosen 1 , Nils Olav Handegard 1 , Ketil Malde 1, 2
Affiliation
|
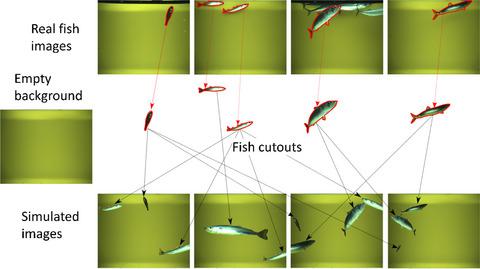
Developing high-performing machine learning algorithms requires large amounts of annotated data. Manual annotation of data is labour-intensive, and the cost and effort needed are an important obstacle to the development and deployment of automated analysis. In a previous work, we have shown that deep learning classifiers can successfully be trained on synthetic images and annotations. Here, we provide a curated set of fish image data and backgrounds, the necessary software tools to generate synthetic images and annotations, and annotated real datasets to test classifier performance. The dataset is constructed from images collected using the Deep Vision system during two surveys from 2017 and 2018 that targeted economically important pelagic species in the Northeast Atlantic Ocean. We annotated a total of 1,879 images, randomly selected across trawl stations from both surveys, comprising 482 images of blue whiting, 456 images of Atlantic herring, 341 images of Atlantic mackerel, 335 images of mesopelagic fishes and 265 images containing a mixture of the four categories.
中文翻译:

用于自动鱼类物种识别的真实世界数据集和数据模拟算法
开发高性能机器学习算法需要大量带注释的数据。数据的手动注释是劳动密集型的,所需的成本和精力是开发和部署自动化分析的重要障碍。在之前的工作中,我们已经证明深度学习分类器可以成功地在合成图像和注释上进行训练。在这里,我们提供了一组精选的鱼图像数据和背景、生成合成图像和注释的必要软件工具,以及用于测试分类器性能的带注释的真实数据集。该数据集是根据在 2017 年和 2018 年的两次调查中使用 Deep Vision 系统收集的图像构建的,这些调查针对东北大西洋具有重要经济意义的中上层物种。我们总共注释了 1,879 张图像,
更新日期:2021-03-18
中文翻译:
用于自动鱼类物种识别的真实世界数据集和数据模拟算法
开发高性能机器学习算法需要大量带注释的数据。数据的手动注释是劳动密集型的,所需的成本和精力是开发和部署自动化分析的重要障碍。在之前的工作中,我们已经证明深度学习分类器可以成功地在合成图像和注释上进行训练。在这里,我们提供了一组精选的鱼图像数据和背景、生成合成图像和注释的必要软件工具,以及用于测试分类器性能的带注释的真实数据集。该数据集是根据在 2017 年和 2018 年的两次调查中使用 Deep Vision 系统收集的图像构建的,这些调查针对东北大西洋具有重要经济意义的中上层物种。我们总共注释了 1,879 张图像,










































 京公网安备 11010802027423号
京公网安备 11010802027423号