Computers & Electrical Engineering ( IF 4.0 ) Pub Date : 2021-03-03 , DOI: 10.1016/j.compeleceng.2021.107032 R. Jothi , Sraban Kumar Mohanty , Aparajita Ojha
|
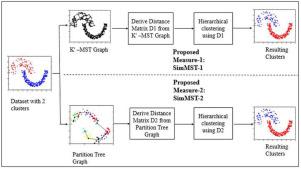
Gene co-expression analysis is an important research problem in molecular biology that helps to identify co-occurring genes in potential biological function. Clustering methods have been widely employed for this problem and hierarchical clustering based gene expression analysis has made tremendous progress in the past years. However, these methods heavily rely on proximity measures used in the clustering process. One of the major issues of hierarchical clustering is their inability to detect arbitrary shaped clusters in high dimensional spaces. Another issue is their pre-requisite of distance matrix calculation, which is not computationally efficient for large datasets. To address these issues, this paper proposes approximate similarity measures based on local neighborhood representation using minimum spanning tree. The effectiveness of proposed similarity measures is tested using hierarchical clustering algorithm. Experimental results on microarray gene expression datasets reveal that the proposed similarity measures achieve improved results in terms of clustering accuracy as well as reduced time complexity as compared to conventional distance measures.
中文翻译:
使用基于局部邻域的相似性度量进行基因表达聚类
基因共表达分析是分子生物学中一个重要的研究问题,有助于鉴定潜在生物学功能中的共现基因。聚类方法已被广泛用于此问题,并且基于分层聚类的基因表达分析在过去几年中已取得了巨大进展。但是,这些方法严重依赖于聚类过程中使用的邻近度度量。层次聚类的主要问题之一是它们无法检测高维空间中的任意形状的聚类。另一个问题是距离矩阵计算的先决条件,这对于大型数据集而言,计算效率不高。为了解决这些问题,本文提出了使用最小生成树的基于局部邻域表示的近似相似性度量。使用分层聚类算法测试了所提出的相似性度量的有效性。在微阵列基因表达数据集上的实验结果表明,与传统的距离度量相比,拟议的相似性度量在聚类精度以及降低的时间复杂度方面均获得了改进的结果。










































 京公网安备 11010802027423号
京公网安备 11010802027423号