Energy and Buildings ( IF 6.6 ) Pub Date : 2021-03-02 , DOI: 10.1016/j.enbuild.2021.110860 Zhipeng Deng , Qingyan Chen
|
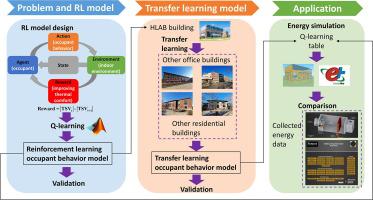
Occupant behavior plays an important role in the evaluation of building performance. However, many contextual factors, such as occupancy, mechanical system and interior design, have a significant impact on occupant behavior. Most previous studies have built data-driven behavior models, which have limited scalability and generalization capability. Our investigation built a policy-based reinforcement learning (RL) model for the behavior of adjusting the thermostat and clothing level. Occupant behavior was modelled as a Markov decision process (MDP). The action and state space in the MDP contained occupant behavior and various impact parameters. The goal of the occupant behavior was a more comfortable environment, and we modelled the reward for the adjustment action as the absolute difference in the thermal sensation vote (TSV) before and after the action. We used Q-learning to train the RL model in MATLAB and validated the model with collected data. After training, the model predicted the behavior of adjusting the thermostat set point with R2 from 0.75 to 0.8, and the mean absolute error (MAE) was less than 1.1 °C (2 °F) in an office building. This study also transferred the behavior knowledge of the RL model to other office buildings with different HVAC control systems. The transfer learning model predicted the occupant behavior with R2 from 0.73 to 0.8, and the MAE was less than 1.1 °C (2 °F) most of the time. Going from office buildings to residential buildings, the transfer learning model also had an R2 over 0.6. Therefore, the RL model combined with transfer learning was able to predict the building occupant behavior accurately with good scalability, and without the need for data collection.
中文翻译:
对跨建筑物转移学习到各种HVAC控制系统的乘员行为模型进行强化学习
乘员行为在评估建筑性能中起着重要作用。但是,许多环境因素,例如占用率,机械系统和室内设计,对占用者的行为有重大影响。以前的大多数研究都建立了数据驱动的行为模型,这些模型具有有限的可伸缩性和泛化能力。我们的调查针对调节恒温器和衣物水平的行为建立了基于策略的强化学习(RL)模型。乘员行为被建模为马尔可夫决策过程(MDP)。MDP中的动作和状态空间包含乘员行为和各种影响参数。乘员行为的目标是营造一个更加舒适的环境,我们将调整动作的奖励建模为动作前后的热感投票(TSV)的绝对差。我们使用Q学习在MATLAB中训练RL模型,并使用收集的数据验证了该模型。训练后,该模型预测了用R调节恒温器设定点的行为2从0.75到0.8,并且办公大楼中的平均绝对误差(MAE)小于1.1°C(2°F)。这项研究还将RL模型的行为知识转移到其他具有不同HVAC控制系统的办公楼中。转移学习模型预测R 2的乘员行为从0.73到0.8,并且MAE大部分时间都低于1.1°C(2°F)。从办公楼到住宅楼,迁移学习模型的R 2也超过0.6。因此,RL模型与转移学习相结合能够以良好的可伸缩性准确预测建筑物的居住者行为,而无需收集数据。










































 京公网安备 11010802027423号
京公网安备 11010802027423号