Journal of Hydrology ( IF 5.9 ) Pub Date : 2021-02-23 , DOI: 10.1016/j.jhydrol.2021.126086 Jenny Sjåstad Hagen , Etienne Leblois , Deborah Lawrence , Dimitri Solomatine , Asgeir Sorteberg
|
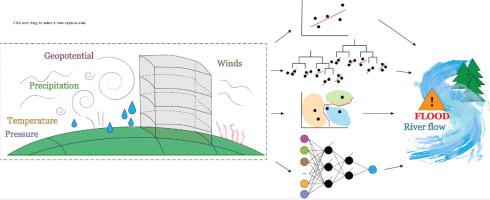
Previous studies linking large-scale atmospheric circulation and river flow with traditional machine learning techniques have predominantly explored monthly, seasonal or annual streamflow modelling for applications in direct downscaling or hydrological climate-impact studies. This paper identifies major drivers of daily streamflow from large-scale atmospheric circulation using two reanalysis datasets for six catchments in Norway representing various Köppen-Geiger climate types and flood-generating processes. A nested loop of roughly pruned random forests is used for feature extraction, demonstrating the potential for automated retrieval of physically consistent and interpretable input variables. Random forest (RF), support vector machine (SVM) for regression and multilayer perceptron (MLP) neural networks are compared to multiple-linear regression to assess the role of model complexity in utilizing the identified major drivers to reconstruct streamflow. The machine learning models were trained on 31 years of aggregated atmospheric data with distinct moving windows for each catchment, reflecting catchment-specific forcing-response relationships between the atmosphere and the rivers. The results show that accuracy improves to some extent with model complexity. In all but the smallest, rainfall-driven catchment, the most complex model, MLP, gives a Nash-Sutcliffe Efficiency (NSE) ranging from 0.71 to 0.81 on testing data spanning five years. The poorer performance by all models in the smallest catchment is discussed in relation to catchment characteristics, sub-grid topography and local variability. The intra-model differences are also viewed in relation to the consistency between the automatically retrieved feature selections from the two reanalysis datasets. This study provides a benchmark for future development of deep learning models for direct downscaling from large-scale atmospheric variables to daily streamflow in Norway.
中文翻译:
通过机器学习识别大规模大气环流中每日流量的主要驱动力
以前将大规模大气环流和河流流量与传统机器学习技术联系起来的研究主要探索了按月,按季节或按年进行的流量模型,以用于直接降尺度或水文气候影响研究。本文使用代表六个柯本-盖革气候类型和洪水发生过程的挪威六个流域的两个再分析数据集,确定了来自大规模大气环流的每日流量的主要驱动因素。粗略修剪的随机森林的嵌套循环用于特征提取,展示了自动检索物理上一致且可解释的输入变量的潜力。随机森林(RF),将用于回归的支持向量机(SVM)和多层感知器(MLP)神经网络与多线性回归进行比较,以评估模型复杂性在利用已识别的主要驱动因素重建流量中的作用。对机器学习模型进行了31年的汇总大气数据训练,每个流域具有不同的移动窗口,反映了大气和河流之间特定于流域的强迫-响应关系。结果表明,随着模型复杂度的提高,精度有所提高。除了最小的,受降雨驱动的集水区以外,最复杂的模型MLP在为期五年的测试数据中得出的纳什-舒特克利夫效率(NSE)为0.71至0.81。讨论了所有模型在最小集水量方面较差的性能,并讨论了集水量特征,亚网格地形和局部变异性。还可以从两个重新分析数据集中自动检索的特征选择之间的一致性方面查看模型内差异。该研究为深度学习模型的未来发展提供了基准,该模型将直接从大规模大气变量缩减到挪威的日常流量。










































 京公网安备 11010802027423号
京公网安备 11010802027423号