当前位置:
X-MOL 学术
›
Softw. Test. Verif. Reliab.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
CSSG: A cost-sensitive stacked generalization approach for software defect prediction
Software Testing, Verification and Reliability ( IF 1.5 ) Pub Date : 2021-02-08 , DOI: 10.1002/stvr.1761 Zeinab Eivazpour 1 , Mohammad Reza Keyvanpour 2
Software Testing, Verification and Reliability ( IF 1.5 ) Pub Date : 2021-02-08 , DOI: 10.1002/stvr.1761 Zeinab Eivazpour 1 , Mohammad Reza Keyvanpour 2
Affiliation
|
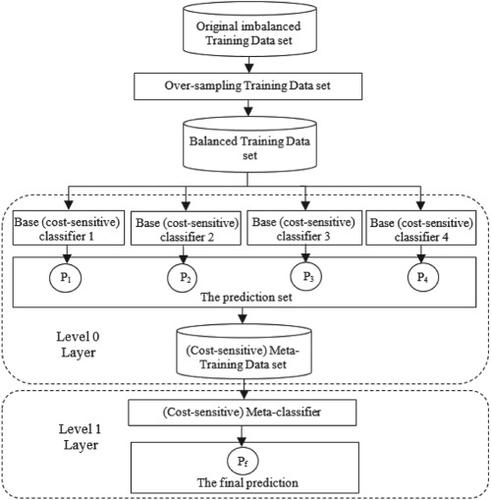
The prediction of software artifacts on defect-prone (DP) or non-defect-prone (NDP) classes during the testing phase helps minimize software business costs, which is a classification task in software defect prediction (SDP) field. Machine learning methods are helpful for the task, although they face the challenge of data imbalance distribution. The challenge leads to serious misclassification of artifacts, which will disrupt the predictor's performance. The previously developed stacking ensemble methods do not consider the cost issue to handle the class imbalance problem (CIP) over the training dataset in the SDP field. To bridge this research gap, in the cost-sensitive stacked generalization (CSSG) approach, we try to combine the staking ensemble learning method with cost-sensitive learning (CSL) since the CSL purpose is to reduce misclassification costs. In the cost-sensitive stacked generalization (CSSG) approach, logistic regression (LR) and extremely randomized trees classifiers in cases of CSL and cost-insensitive are used as a final classifier of stacking scheme. To evaluate the performance of CSSG, we use six performance measures. Several experiments are carried out to compare the CSSG with some cost-sensitive ensemble methods on 15 benchmark datasets with different imbalance levels. The results indicate that the CSSG can be an effective solution to the CIP than other compared methods.
中文翻译:

CSSG:一种用于软件缺陷预测的成本敏感的堆叠泛化方法
在测试阶段对缺陷易发 (DP) 或非缺陷易发 (NDP) 类的软件工件进行预测有助于最大限度地降低软件业务成本,这是软件缺陷预测 (SDP) 领域的分类任务。机器学习方法对这项任务很有帮助,尽管它们面临着数据不平衡分布的挑战。该挑战导致对工件的严重错误分类,这将破坏预测器的性能。先前开发的堆叠集成方法没有考虑处理 SDP 领域训练数据集上的类不平衡问题 (CIP) 的成本问题。为了弥合这一研究差距,在成本敏感的堆叠泛化 (CSSG) 方法中,我们尝试将 staking 集成学习方法与成本敏感学习 (CSL) 相结合,因为 CSL 的目的是减少错误分类成本。在成本敏感的堆叠泛化 (CSSG) 方法中,逻辑回归 (LR) 和 CSL 和成本不敏感情况下的极端随机树分类器用作堆叠方案的最终分类器。为了评估 CSSG 的性能,我们使用了六个性能指标。进行了几个实验,以在 15 个具有不同不平衡水平的基准数据集上将 CSSG 与一些成本敏感的集成方法进行比较。结果表明,与其他比较方法相比,CSSG 是 CIP 的有效解决方案。在 CSL 和成本不敏感的情况下,逻辑回归 (LR) 和极其随机的树分类器被用作堆叠方案的最终分类器。为了评估 CSSG 的性能,我们使用了六个性能指标。进行了几个实验,以在 15 个具有不同不平衡水平的基准数据集上将 CSSG 与一些成本敏感的集成方法进行比较。结果表明,与其他比较方法相比,CSSG 是 CIP 的有效解决方案。在 CSL 和成本不敏感的情况下,逻辑回归 (LR) 和极其随机的树分类器被用作堆叠方案的最终分类器。为了评估 CSSG 的性能,我们使用了六个性能指标。进行了几个实验,以在 15 个具有不同不平衡水平的基准数据集上将 CSSG 与一些成本敏感的集成方法进行比较。结果表明,与其他比较方法相比,CSSG 是 CIP 的有效解决方案。
更新日期:2021-02-08
中文翻译:
CSSG:一种用于软件缺陷预测的成本敏感的堆叠泛化方法
在测试阶段对缺陷易发 (DP) 或非缺陷易发 (NDP) 类的软件工件进行预测有助于最大限度地降低软件业务成本,这是软件缺陷预测 (SDP) 领域的分类任务。机器学习方法对这项任务很有帮助,尽管它们面临着数据不平衡分布的挑战。该挑战导致对工件的严重错误分类,这将破坏预测器的性能。先前开发的堆叠集成方法没有考虑处理 SDP 领域训练数据集上的类不平衡问题 (CIP) 的成本问题。为了弥合这一研究差距,在成本敏感的堆叠泛化 (CSSG) 方法中,我们尝试将 staking 集成学习方法与成本敏感学习 (CSL) 相结合,因为 CSL 的目的是减少错误分类成本。在成本敏感的堆叠泛化 (CSSG) 方法中,逻辑回归 (LR) 和 CSL 和成本不敏感情况下的极端随机树分类器用作堆叠方案的最终分类器。为了评估 CSSG 的性能,我们使用了六个性能指标。进行了几个实验,以在 15 个具有不同不平衡水平的基准数据集上将 CSSG 与一些成本敏感的集成方法进行比较。结果表明,与其他比较方法相比,CSSG 是 CIP 的有效解决方案。在 CSL 和成本不敏感的情况下,逻辑回归 (LR) 和极其随机的树分类器被用作堆叠方案的最终分类器。为了评估 CSSG 的性能,我们使用了六个性能指标。进行了几个实验,以在 15 个具有不同不平衡水平的基准数据集上将 CSSG 与一些成本敏感的集成方法进行比较。结果表明,与其他比较方法相比,CSSG 是 CIP 的有效解决方案。在 CSL 和成本不敏感的情况下,逻辑回归 (LR) 和极其随机的树分类器被用作堆叠方案的最终分类器。为了评估 CSSG 的性能,我们使用了六个性能指标。进行了几个实验,以在 15 个具有不同不平衡水平的基准数据集上将 CSSG 与一些成本敏感的集成方法进行比较。结果表明,与其他比较方法相比,CSSG 是 CIP 的有效解决方案。










































 京公网安备 11010802027423号
京公网安备 11010802027423号