Computers & Graphics ( IF 2.5 ) Pub Date : 2021-02-05 , DOI: 10.1016/j.cag.2021.01.013 Ishaan Lodha
|
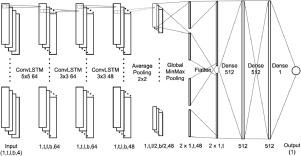
There has been an unprecedented explosion in creation and consumption of high definition videos and images. This has led to the development and adoption of several systems which manipulate graphic content. Most of these systems require a robust, no-reference, domain independent, and subjective quality metric. The state-of-the-art algorithms aimed at no-reference quality assessment of images and videos employ neural networks that are content domain dependent and require application specific training. Further, present systems are trained to estimate quality metric in accordance to objective metrics such as Peak Signal to Noise Ratio or Mean Squared Error. We propose a convolutional neural network architecture that leverages a variable length long short term memory. The model will also make use of the Laplacian as a fourth layer in the input to ensure content domain independence in quality estimation. The system has been trained on the images of KonIQ-10K dataset and tested on KonViD-1k video dataset and LIVE video dataset. It has also been tested on 1000 frames and videos from the VIRAT dataset and images from BSD300 and Set5 datasets with artificial blur and distortion applied. The quality estimations were compared to the mean opinion square given by five human viewers and resulted in a 11% root mean squared error. Thus the proposed model provides a subjective quality estimation of graphic content without any dependence on the domain of the content.
中文翻译:
域无关图像和视频的主观和无参考质量度量
高清晰度视频和图像的创建和消费已经发生了前所未有的爆炸式增长。这导致开发和采用了几种操纵图形内容的系统。这些系统中的大多数都需要强大的,无引用的,独立于域的和主观的质量指标。旨在对图像和视频进行无参考质量评估的最新算法采用了依赖于内容域的神经网络,并且需要针对特定应用进行培训。此外,当前系统被训练以根据诸如峰值信噪比或均方误差之类的客观度量来估计质量度量。我们提出了一种卷积神经网络体系结构,该体系结构利用了可变长度的长期短期记忆。该模型还将在输入中使用拉普拉斯算子作为第四层,以确保内容域在质量估计中的独立性。该系统已经在KonIQ-10K数据集的图像上进行了训练,并在KonViD-1k视频数据集和LIVE视频数据集上进行了测试。还对VIRAT数据集的1000帧和视频以及BSD300和Set5数据集的图像应用了人工模糊和失真进行了测试。将质量估算值与五位观众的平均意见平方进行比较,得出11%的均方根误差。因此,所提出的模型提供了图形内容的主观质量估计,而不依赖于内容的域。该系统已经在KonIQ-10K数据集的图像上进行了训练,并在KonViD-1k视频数据集和LIVE视频数据集上进行了测试。还对VIRAT数据集的1000帧和视频以及BSD300和Set5数据集的图像应用了人工模糊和失真进行了测试。将质量估算值与五位观众的平均意见平方进行比较,得出11%的均方根误差。因此,所提出的模型提供了图形内容的主观质量估计,而不依赖于内容的域。该系统已针对KonIQ-10K数据集的图像进行了训练,并在KonViD-1k视频数据集和LIVE视频数据集上进行了测试。还对VIRAT数据集的1000帧和视频以及BSD300和Set5数据集的图像应用了人工模糊和失真进行了测试。将质量估算值与五位观众的平均意见平方进行比较,得出11%的均方根误差。因此,所提出的模型提供了图形内容的主观质量估计,而不依赖于内容的域。将质量估算值与五位观众的平均意见平方进行比较,得出11%的均方根误差。因此,所提出的模型提供了图形内容的主观质量估计,而不依赖于内容的域。将质量估算值与五位观众的平均意见平方进行比较,得出11%的均方根误差。因此,所提出的模型提供了图形内容的主观质量估计,而不依赖于内容的域。










































 京公网安备 11010802027423号
京公网安备 11010802027423号