Ecological Modelling ( IF 2.6 ) Pub Date : 2021-02-02 , DOI: 10.1016/j.ecolmodel.2021.109453 Camille Van Eupen , Dirk Maes , Marc Herremans , Kristijn R.R. Swinnen , Ben Somers , Stijn Luca
|
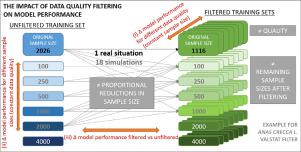
Opportunistically collected species occurrence data are often used for species distribution models (SDMs) when high-quality data collected through standardized recording protocols are unavailable. While opportunistic data are abundant, uncertainty is usually high, e.g. due to observer effects or a lack of metadata. To increase data quality and improve model performance, we filtered species records based on record attributes that provide information on the observation process or post-entry data validation. Data filtering does not only increase the quality of species records, it simultaneously reduces sample size, a trade-off that remains relatively unexplored. By controlling for sample size in a dataset of 255 species, we were able to explore the combined impact of data quality and sample size on model performance. We applied three data quality filters based on observers' activity, the validation status of a record in the database and the detail of a submitted record, and analyzed changes in AUC, Sensitivity and Specificity using Maxent with and without filtering. The impact of stringent filtering on model performance depended on (1) the quality of the filtered data: records validated as correct and more detailed records lead to higher model performance, (2) the proportional reduction in sample size caused by filtering and the remaining absolute sample size: filters causing small reductions that lead to sample sizes of more than 100 presences generally benefitted model performance and (3) the taxonomic group: plant and dragonfly models benefitted more from data quality filtering compared to bird and butterfly models. Our results also indicate that recommendations for quality filtering depend on the goal of the study, e.g. increasing Sensitivity and/or Specificity. Further research must identify what drives species’ sensitivity to data quality. Nonetheless, our study confirms that large quantities of volunteer generated and opportunistically collected data can make a valuable contribution to ecological research and species conservation.
中文翻译:
机会公民科学数据的数据质量过滤对物种分布模型性能的影响
当无法通过标准记录协议收集高质量的数据时,机会收集的物种发生数据通常用于物种分布模型(SDM)。尽管机会数据丰富,但是不确定性通常很高,例如由于观察者的影响或缺少元数据。为了提高数据质量并改善模型性能,我们根据记录属性过滤了物种记录,这些记录属性提供了有关观察过程或进入后数据验证的信息。数据过滤不仅可以提高物种记录的质量,而且可以同时减少样本数量,但这种权衡取舍尚待探索。通过控制255种数据集中的样本量,我们能够探索数据质量和样本量对模型性能的综合影响。我们基于观察者的活动,数据库中记录的确认状态和提交的记录的详细信息应用了三个数据质量过滤器,并使用了带和不带过滤的Maxent分析了AUC,灵敏度和特异性的变化。严格过滤对模型性能的影响取决于(1)过滤后数据的质量:验证为正确且更详细的记录会导致更高的模型性能;(2)过滤导致的样本量成比例减少以及剩余的绝对值样本大小:过滤器引起的小幅减少,导致样本数量超过100个,通常有益于模型性能;(3)分类组:与鸟类和蝴蝶模型相比,植物和蜻蜓模型从数据质量过滤中受益更多。我们的结果还表明,针对质量过滤的建议取决于研究的目标,例如,提高敏感性和/或特异性。进一步的研究必须确定是什么驱动物种对数据质量的敏感性。但是,我们的研究证实,大量志愿者生成和机会收集的数据可以为生态研究和物种保护做出宝贵的贡献。










































 京公网安备 11010802027423号
京公网安备 11010802027423号