Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Vocal development in a large-scale crosslinguistic corpus
Developmental Science ( IF 3.1 ) Pub Date : 2021-01-26 , DOI: 10.1111/desc.13090 Margaret Cychosz 1 , Alejandrina Cristia 2 , Elika Bergelson 3 , Marisa Casillas 4 , Gladys Baudet 3 , Anne S Warlaumont 5 , Camila Scaff 2, 6 , Lisa Yankowitz 7 , Amanda Seidl 8
Developmental Science ( IF 3.1 ) Pub Date : 2021-01-26 , DOI: 10.1111/desc.13090 Margaret Cychosz 1 , Alejandrina Cristia 2 , Elika Bergelson 3 , Marisa Casillas 4 , Gladys Baudet 3 , Anne S Warlaumont 5 , Camila Scaff 2, 6 , Lisa Yankowitz 7 , Amanda Seidl 8
Affiliation
|
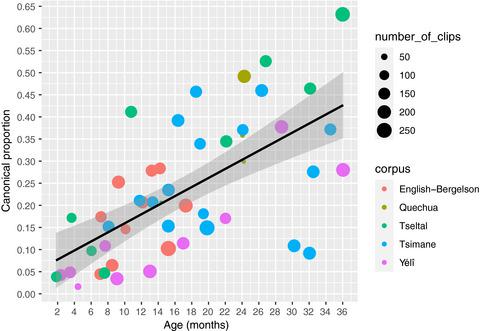
This study evaluates whether early vocalizations develop in similar ways in children across diverse cultural contexts. We analyze data from daylong audio recordings of 49 children (1–36 months) from five different language/cultural backgrounds. Citizen scientists annotated these recordings to determine if child vocalizations contained canonical transitions or not (e.g., “ba” vs. “ee”). Results revealed that the proportion of clips reported to contain canonical transitions increased with age. Furthermore, this proportion exceeded 0.15 by around 7 months, replicating and extending previous findings on canonical vocalization development but using data from the natural environments of a culturally and linguistically diverse sample. This work explores how crowdsourcing can be used to annotate corpora, helping establish developmental milestones relevant to multiple languages and cultures. Lower inter-annotator reliability on the crowdsourcing platform, relative to more traditional in-lab expert annotators, means that a larger number of unique annotators and/or annotations are required, and that crowdsourcing may not be a suitable method for more fine-grained annotation decisions. Audio clips used for this project are compiled into a large-scale infant vocalization corpus that is available for other researchers to use in future work.
中文翻译:

大规模跨语言语料库中的声音发展
这项研究评估了不同文化背景下的儿童早期发声是否以相似的方式发展。我们分析了来自五种不同语言/文化背景的 49 名儿童(1-36 个月)的全天录音数据。公民科学家对这些录音进行了注释,以确定儿童发声是否包含规范转换(例如“ba”与“ee”)。结果显示,据报道包含规范过渡的剪辑比例随着年龄的增长而增加。此外,这一比例在大约 7 个月内超过了 0.15,复制并扩展了之前关于规范发声发展的发现,但使用了来自文化和语言多样化样本的自然环境的数据。这项工作探讨了如何使用众包来注释语料库,帮助建立与多种语言和文化相关的发展里程碑。相对于更传统的实验室专家注释者,众包平台上注释者间的可靠性较低,这意味着需要大量独特的注释者和/或注释,并且众包可能不是更细粒度注释的合适方法决定。该项目使用的音频剪辑被编译成一个大规模的婴儿发声语料库,可供其他研究人员在未来的工作中使用。
更新日期:2021-01-26
中文翻译:
大规模跨语言语料库中的声音发展
这项研究评估了不同文化背景下的儿童早期发声是否以相似的方式发展。我们分析了来自五种不同语言/文化背景的 49 名儿童(1-36 个月)的全天录音数据。公民科学家对这些录音进行了注释,以确定儿童发声是否包含规范转换(例如“ba”与“ee”)。结果显示,据报道包含规范过渡的剪辑比例随着年龄的增长而增加。此外,这一比例在大约 7 个月内超过了 0.15,复制并扩展了之前关于规范发声发展的发现,但使用了来自文化和语言多样化样本的自然环境的数据。这项工作探讨了如何使用众包来注释语料库,帮助建立与多种语言和文化相关的发展里程碑。相对于更传统的实验室专家注释者,众包平台上注释者间的可靠性较低,这意味着需要大量独特的注释者和/或注释,并且众包可能不是更细粒度注释的合适方法决定。该项目使用的音频剪辑被编译成一个大规模的婴儿发声语料库,可供其他研究人员在未来的工作中使用。










































 京公网安备 11010802027423号
京公网安备 11010802027423号