当前位置:
X-MOL 学术
›
Energy Fuels
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Predictive Capability Assessment of Probabilistic Machine Learning Models for Density Prediction of Conventional and Synthetic Jet Fuels
Energy & Fuels ( IF 5.2 ) Pub Date : 2021-01-21 , DOI: 10.1021/acs.energyfuels.0c03779 Clemens Hall 1 , Bastian Rauch 1 , Uwe Bauder 1 , Patrick Le Clercq 1 , Manfred Aigner 1
Energy & Fuels ( IF 5.2 ) Pub Date : 2021-01-21 , DOI: 10.1021/acs.energyfuels.0c03779 Clemens Hall 1 , Bastian Rauch 1 , Uwe Bauder 1 , Patrick Le Clercq 1 , Manfred Aigner 1
Affiliation
|
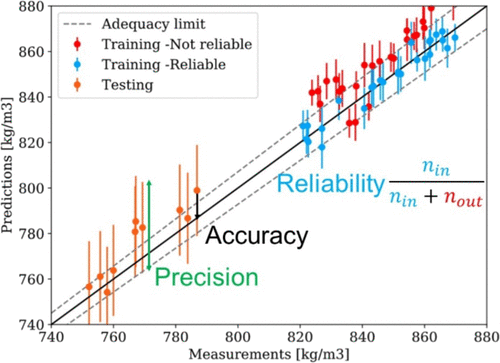
Machine Learning (ML) models are increasingly applied in the field of jet fuel property predictions due to their ability of modeling a high number of complex composition–property relationships directly on measurement data. Their applicability is still limited as for safety relevant use cases like synthetic fuel approval or aircraft design consequences of prediction errors might be too severe to be acceptable. For Machine Learning algorithms, the predictive capability strongly depends on the data utilized for the training of the models. Predictions for fuels that differ from the training data might have uncertainties that need to be systematically considered. We present an approach of utilizing the probabilistic ML algorithm Gaussian Process Regression to model jet fuel properties and estimate the uncertainty that results from limited training data. We apply this approach for the example of density over a range of −40 to 140 °C. To assess the influence of synthetic fuels on the predictive capability, two models are studied, one trained exclusively on conventional fuels data and the other one trained on the same conventional fuels and additional synthetic fuels. To quantify the predictive capability of the models, we introduce three metrics that measure the accuracy and precision of the prediction as well as the validity and reliability of the estimated prediction interval. Results show that prediction intervals can correctly be estimated by both models and a valid estimation of the predictive capability is possible. Furthermore, the addition of synthetic fuels data drastically improves the accuracy, reduces the uncertainty, and is necessary to achieve adequate predictions for the considered hold-out fuels.
中文翻译:

常规和合成喷气燃料密度预测的概率机器学习模型的预测能力评估
机器学习(ML)模型能够直接在测量数据上建模大量复杂的成分-性质关系,因此越来越多地应用于喷气燃料性质预测领域。它们的适用性仍然受到限制,因为对于安全相关的用例,例如合成燃料批准或预测错误的飞机设计后果,可能过于严重,无法接受。对于机器学习算法,预测能力在很大程度上取决于用于训练模型的数据。与训练数据不同的燃料预测可能具有不确定性,需要系统地加以考虑。我们提出一种利用概率ML算法高斯过程回归来对喷气燃料特性进行建模并估算由有限训练数据所导致的不确定性的方法。我们以这种方法为例,介绍了在−40至140°C范围内的密度。为了评估合成燃料对预测能力的影响,研究了两种模型,一种模型专门训练常规燃料数据,另一种模型训练相同常规燃料和其他合成燃料。为了量化模型的预测能力,我们引入了三个度量标准,用于测量预测的准确性和精确度以及估计的预测间隔的有效性和可靠性。结果表明,可以通过两个模型正确估计预测间隔,并且可以对预测能力进行有效估计。此外,合成燃料数据的添加大大提高了准确性,减少了不确定性,
更新日期:2021-02-04
中文翻译:
常规和合成喷气燃料密度预测的概率机器学习模型的预测能力评估
机器学习(ML)模型能够直接在测量数据上建模大量复杂的成分-性质关系,因此越来越多地应用于喷气燃料性质预测领域。它们的适用性仍然受到限制,因为对于安全相关的用例,例如合成燃料批准或预测错误的飞机设计后果,可能过于严重,无法接受。对于机器学习算法,预测能力在很大程度上取决于用于训练模型的数据。与训练数据不同的燃料预测可能具有不确定性,需要系统地加以考虑。我们提出一种利用概率ML算法高斯过程回归来对喷气燃料特性进行建模并估算由有限训练数据所导致的不确定性的方法。我们以这种方法为例,介绍了在−40至140°C范围内的密度。为了评估合成燃料对预测能力的影响,研究了两种模型,一种模型专门训练常规燃料数据,另一种模型训练相同常规燃料和其他合成燃料。为了量化模型的预测能力,我们引入了三个度量标准,用于测量预测的准确性和精确度以及估计的预测间隔的有效性和可靠性。结果表明,可以通过两个模型正确估计预测间隔,并且可以对预测能力进行有效估计。此外,合成燃料数据的添加大大提高了准确性,减少了不确定性,










































 京公网安备 11010802027423号
京公网安备 11010802027423号