Neurocomputing ( IF 5.5 ) Pub Date : 2021-01-18 , DOI: 10.1016/j.neucom.2021.01.033 J. Hoyos-Osorio , A. Alvarez-Meza , G. Daza-Santacoloma , A. Orozco-Gutierrez , G. Castellanos-Dominguez
|
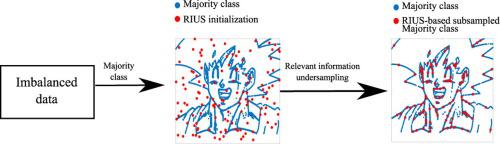
Traditional classification algorithms suppose that the sample distribution among classes is balanced. Yet, such an assumption leads to biased performance over the majority class. This paper proposes a Relevant Information-based UnderSampling (RIUS) approach to select the most relevant examples from the majority class to improve the classification performance for imbalanced data scenarios. RIUS builds on the information-preservation principle that extracts the majority class’s underlying structure with fewer samples. Additionally, we couple our RIUS approach to the well-known Clustering-based Undersampling algorithm (CBUS) to enhance the data representation, and named this RIUS enhancement as CRIUS. Experimental results show that RIUS and CRIUS reveal the data’s relevant structure and reduce the loss of information by selecting the most informative instances.
中文翻译:
相关信息欠采样以支持不平衡的数据分类
传统的分类算法假定类别之间的样本分布是平衡的。然而,这样的假设导致大多数阶层的员工表现有偏见。本文提出了一种基于相关信息的欠采样(RIUS)方法,从多数类中选择最相关的示例,以提高不平衡数据方案的分类性能。RIUS建立在信息保留原则的基础上,该原则提取具有较少样本的多数类的基础结构。此外,我们将RIUS方法与著名的基于聚类的欠采样算法(CBUS)结合使用以增强数据表示,并将此RIUS增强功能称为CRIUS。










































 京公网安备 11010802027423号
京公网安备 11010802027423号