Image and Vision Computing ( IF 4.2 ) Pub Date : 2021-01-06 , DOI: 10.1016/j.imavis.2021.104096 Le Thanh Nguyen-Meidine , Atif Belal , Madhu Kiran , Jose Dolz , Louis-Antoine Blais-Morin , Eric Granger
|
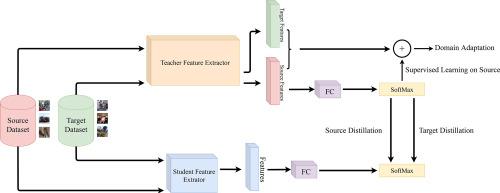
Beyond the complexity of CNNs that require training on large annotated datasets, the domain shift between design and operational data has limited the adoption of CNNs in many real-world applications. For instance, in person re-identification, videos are captured over a distributed set of cameras with non-overlapping viewpoints. The shift between the source (e.g. lab setting) and target (e.g. cameras) domains may lead to a significant decline in recognition accuracy. Additionally, state-of-the-art CNNs may not be suitable for such real-time applications given their computational requirements. Although several techniques have recently been proposed to address domain shift problems through unsupervised domain adaptation (UDA), or to accelerate/compress CNNs through knowledge distillation (KD), we seek to simultaneously adapt and compress CNNs to generalize well across multiple target domains. In this paper, we propose a progressive KD approach for unsupervised single-target DA (STDA) and multi-target DA (MTDA) of CNNs. Our method for KD-STDA adapts a CNN to a single target domain by distilling from a larger teacher CNN, trained on both target and source domain data in order to maintain its consistency with a common representation. This method is extended to address MTDA problems, where multiple teachers are used to distill multiple target domain knowledge to a common student CNN. A different target domain is assigned to each teacher model for UDA, and they alternatively distill their knowledge to the student model to preserve specificity of each target, instead of directly combining the knowledge from each teacher using fusion methods. Our proposed approach is compared against state-of-the-art methods for compression and STDA of CNNs on the Office31 and ImageClef-DA image classification datasets. It is also compared against state-of-the-art methods for MTDA on Digits, Office31, and OfficeHome. In both settings – KD-STDA and KD-MTDA – results indicate that our approach can achieve the highest level of accuracy across target domains, while requiring a comparable or lower CNN complexity.
中文翻译:
知识提炼方法可实现跨多个领域的有效无监督适应
除了需要在大型带注释的数据集上进行训练的CNN的复杂性之外,设计数据和操作数据之间的领域转移还限制了CNN在许多实际应用中的采用。例如,在人员重新识别中,视频是在具有非重叠视点的一组分布式摄像机上捕获的。源(例如实验室设置)域和目标(例如相机)域之间的转换可能导致识别准确性的显着下降。此外,鉴于其计算要求,最新的CNN可能不适合此类实时应用。尽管最近提出了几种技术来通过无监督域自适应(UDA)解决域转换问题,或通过知识蒸馏(KD)加速/压缩CNN,我们力求同时适应和压缩CNN,以在多个目标域中很好地泛化。在本文中,我们为CNN的无监督单目标DA(STDA)和多目标DA(MTDA)提出了一种渐进式KD方法。我们的KD-STDA方法是通过从较大的教师CNN中提炼出来的CNN适应单个目标域的,该CNN在目标域和源域数据上进行了训练,以保持其与通用表示的一致性。此方法已扩展为解决MTDA问题,其中使用多个老师将多个目标领域的知识提炼到普通学生的CNN中。为UDA的每个教师模型分配了一个不同的目标领域,他们可以选择将其知识提取到学生模型中以保留每个目标的特异性,而不是使用融合方法将每个教师的知识直接组合在一起。将我们提出的方法与Office31和ImageClef-DA图像分类数据集上CNN压缩和STDA的最新方法进行了比较。还将它与Digits,Office31和OfficeHome上的MTDA的最新方法进行了比较。在KD-STDA和KD-MTDA两种设置中,结果都表明,我们的方法可以在目标域中实现最高的准确性,同时需要相当或更低的CNN复杂度。










































 京公网安备 11010802027423号
京公网安备 11010802027423号