Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2020-12-25 , DOI: 10.1016/j.jbi.2020.103667 Luca Bonomi 1 , Liyue Fan 2 , Xiaoqian Jiang 3
|
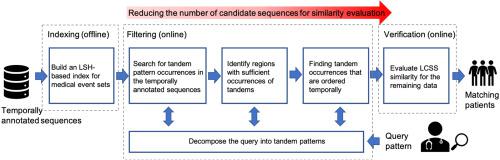
Temporal medical data are increasingly integrated into the development of data-driven methods to deliver better healthcare. Searching such data for patterns can improve the detection of disease cases and facilitate the design of preemptive interventions. For example, specific temporal patterns could be used to recognize low-prevalence diseases, which are often under-diagnosed. However, searching these patterns in temporal medical data is challenging, as the data are often noisy, complex, and large in scale. In this work, we propose an effective and efficient solution to search for patients who exhibit conditions that resemble the input query. In our solution, we propose a similarity notion based on the Longest Common Subsequence (LCSS), which is used to measure the similarity between the query and the patient’s temporal medical data and to ensure robustness against noise in the data. Our solution adopts locality sensitive hashing techniques to address the high dimensionality of medical data, by embedding the recorded clinical events (e.g., medications and diagnosis codes) into compact signatures. To perform pattern search in large EHR datasets, we propose a filtering approach based on tandem patterns, which effectively identifies candidate matches while discarding irrelevant data. The evaluations conducted using a real-world dataset demonstrate that our solution is highly accurate while significantly accelerating the similarity search.
中文翻译:
时态医学数据中的容噪相似性搜索
时间医疗数据越来越多地集成到数据驱动方法的开发中,以提供更好的医疗保健。搜索此类数据的模式可以提高对疾病病例的检测,并有助于设计先发制人的干预措施。例如,可以使用特定的时间模式来识别低流行病,而这些疾病往往诊断不足。然而,在时间医学数据中搜索这些模式是具有挑战性的,因为数据通常嘈杂、复杂且规模庞大。在这项工作中,我们提出了一种有效且高效的解决方案来搜索表现出与输入查询相似的条件的患者。在我们的解决方案中,我们提出了基于最长公共子序列 (LCSS) 的相似性概念,它用于衡量查询与患者的时间医学数据之间的相似性,并确保对数据中的噪声具有鲁棒性。我们的解决方案采用局部敏感散列技术,通过将记录的临床事件(例如,药物和诊断代码)嵌入到紧凑的签名中来解决医疗数据的高维问题。为了在大型 EHR 数据集中执行模式搜索,我们提出了一种基于串联模式的过滤方法,该方法可以有效识别候选匹配项,同时丢弃不相关的数据。使用真实世界数据集进行的评估表明,我们的解决方案高度准确,同时显着加速了相似性搜索。通过将记录的临床事件(例如,药物和诊断代码)嵌入到紧凑的签名中。为了在大型 EHR 数据集中执行模式搜索,我们提出了一种基于串联模式的过滤方法,该方法可以有效识别候选匹配项,同时丢弃不相关的数据。使用真实世界数据集进行的评估表明,我们的解决方案高度准确,同时显着加速了相似性搜索。通过将记录的临床事件(例如,药物和诊断代码)嵌入到紧凑的签名中。为了在大型 EHR 数据集中执行模式搜索,我们提出了一种基于串联模式的过滤方法,该方法可以有效识别候选匹配项,同时丢弃不相关的数据。使用真实世界数据集进行的评估表明,我们的解决方案高度准确,同时显着加速了相似性搜索。


























 京公网安备 11010802027423号
京公网安备 11010802027423号