Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-12-15 , DOI: 10.1016/j.jbi.2020.103665 Timothy L Chen 1 , Max Emerling 2 , Gunvant R Chaudhari 3 , Yeshwant R Chillakuru 4 , Youngho Seo 3 , Thienkhai H Vu 3 , Jae Ho Sohn 3
|
Background
There has been increasing interest in machine learning based natural language processing (NLP) methods in radiology; however, models have often used word embeddings trained on general web corpora due to lack of a radiology-specific corpus.
Purpose
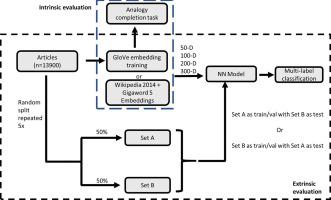
We examined the potential of Radiopaedia to serve as a general radiology corpus to produce radiology specific word embeddings that could be used to enhance performance on a NLP task on radiological text.
Materials and methods
Embeddings of dimension 50, 100, 200, and 300 were trained on articles collected from Radiopaedia using a GloVe algorithm and evaluated on analogy completion. A shallow neural network using input from either our trained embeddings or pre-trained Wikipedia 2014 + Gigaword 5 (WG) embeddings was used to label the Radiopaedia articles. Labeling performance was evaluated based on exact match accuracy and Hamming loss. The McNemar’s test with continuity and the Benjamini-Hochberg correction and a 5×2 cross validation paired two-tailed t-test were used to assess statistical significance.
Results
For accuracy in the analogy task, 50-dimensional (50-D) Radiopaedia embeddings outperformed WG embeddings on tumor origin analogies (p < 0.05) and organ adjectives (p < 0.01) whereas WG embeddings tended to outperform on inflammation location and bone vs. muscle analogies (p < 0.01). The two embeddings had comparable performance on other subcategories. In the labeling task, the Radiopaedia-based model outperformed the WG based model at 50, 100, 200, and 300-D for exact match accuracy (p < 0.001, p < 0.001, p < 0.01, and p < 0.05, respectively) and Hamming loss (p < 0.001, p < 0.001, p < 0.01, and p < 0.05, respectively).
Conclusion
We have developed a set of word embeddings from Radiopaedia and shown that they can preserve relevant medical semantics and augment performance on a radiology NLP task. Our results suggest that the cultivation of a radiology-specific corpus can benefit radiology NLP models in the future.
中文翻译:
用于放射学自然语言处理的领域特定词嵌入
背景
人们对放射学中基于机器学习的自然语言处理(NLP)方法越来越感兴趣;然而,由于缺乏放射学特定的语料库,模型经常使用在通用网络语料库上训练的词嵌入。
目的
我们研究了 Radiopaedia 作为通用放射学语料库来生成放射学特定词嵌入的潜力,这些词嵌入可用于增强放射学文本 NLP 任务的性能。
材料和方法
使用 GloVe 算法对从 Radiopaedia 收集的文章训练维度 50、100、200 和 300 的嵌入,并根据类比完成进行评估。使用来自我们经过训练的嵌入或预先训练的 Wikipedia 2014 + Gigaword 5 (WG) 嵌入的输入的浅层神经网络用于标记 Radiopaedia 文章。根据精确匹配精度和汉明损失评估标记性能。McNemar 连续性检验、Benjamini-Hochberg 校正和 5×2 交叉验证配对双尾t检验用于评估统计显着性。
结果
就类比任务的准确性而言,50 维 (50-D) 放射百科嵌入在肿瘤起源类比 (p < 0.05) 和器官形容词 (p < 0.01) 方面优于 WG 嵌入,而 WG 嵌入在炎症位置和骨骼与骨骼方面往往优于 WG 嵌入。肌肉类比(p < 0.01)。这两种嵌入在其他子类别上的表现相当。在标记任务中,基于 Radiopaedia 的模型在 50、100、200 和 300-D 的精确匹配精度方面优于基于 WG 的模型(分别为 p < 0.001、p < 0.001、p < 0.01 和 p < 0.05)和汉明损失(分别为 p < 0.001、p < 0.001、p < 0.01 和 p < 0.05)。
结论
我们从 Radiopaedia 开发了一组词嵌入,并证明它们可以保留相关的医学语义并增强放射学 NLP 任务的性能。我们的结果表明,放射学专用语料库的培养可以使未来的放射学 NLP 模型受益。










































 京公网安备 11010802027423号
京公网安备 11010802027423号