Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-12-11 , DOI: 10.1016/j.jbi.2020.103658 William Brown 1 , Renu Balyan 2 , Andrew J Karter 3 , Scott Crossley 4 , Wagahta Semere 5 , Nicholas D Duran 6 , Courtney Lyles 7 , Jennifer Liu 3 , Howard H Moffet 3 , Ryane Daniels 8 , Danielle S McNamara 9 , Dean Schillinger 7
|
Objective
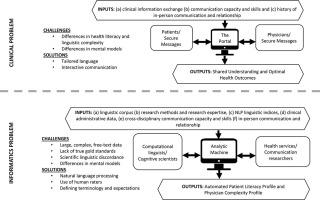
In the National Library of Medicine funded ECLIPPSE Project (Employing Computational Linguistics to Improve Patient-Provider Secure Emails exchange), we attempted to create novel, valid, and scalable measures of both patients’ health literacy (HL) and physicians’ linguistic complexity by employing natural language processing (NLP) techniques and machine learning (ML). We applied these techniques to > 400,000 patients’ and physicians’ secure messages (SMs) exchanged via an electronic patient portal, developing and validating an automated patient literacy profile (LP) and physician complexity profile (CP). Herein, we describe the challenges faced and the solutions implemented during this innovative endeavor.
Materials and methods
To describe challenges and solutions, we used two data sources: study documents and interviews with study investigators. Over the five years of the project, the team tracked their research process using a combination of Google Docs tools and an online team organization, tracking, and management tool (Asana). In year 5, the team convened a number of times to discuss, categorize, and code primary challenges and solutions.
Results
We identified 23 challenges and associated approaches that emerged from three overarching process domains: (1) Data Mining related to the SM corpus; (2) Analyses using NLP indices on the SM corpus; and (3) Interdisciplinary Collaboration. With respect to Data Mining, problems included cleaning SMs to enable analyses, removing hidden caregiver proxies (e.g., other family members) and Spanish language SMs, and culling SMs to ensure that only patients’ primary care physicians were included. With respect to Analyses, critical decisions needed to be made as to which computational linguistic indices and ML approaches should be selected; how to enable the NLP-based linguistic indices tools to run smoothly and to extract meaningful data from a large corpus of medical text; and how to best assess content and predictive validities of both the LP and the CP. With respect to the Interdisciplinary Collaboration, because the research required engagement between clinicians, health services researchers, biomedical informaticians, linguists, and cognitive scientists, continual effort was needed to identify and reconcile differences in scientific terminologies and resolve confusion; arrive at common understanding of tasks that needed to be completed and priorities therein; reach compromises regarding what represents “meaningful findings” in health services vs. cognitive science research; and address constraints regarding potential transportability of the final LP and CP to different health care settings.
Discussion
Our study represents a process evaluation of an innovative research initiative to harness “big linguistic data” to estimate patient HL and physician linguistic complexity. Any of the challenges we identified, if left unaddressed, would have either rendered impossible the effort to generate LPs and CPs, or invalidated analytic results related to the LPs and CPs. Investigators undertaking similar research in HL or using computational linguistic methods to assess patient-clinician exchange will face similar challenges and may find our solutions helpful when designing and executing their health communications research.
中文翻译:
采用自然语言处理和机器学习来衡量患者健康素养和医生写作复杂性的挑战和解决方案:ECLIPPSE 研究
客观的
在国家医学图书馆资助的 ECLIPPSE 项目(采用计算语言学来改善患者与提供者安全的电子邮件交换)中,我们尝试创建新颖、有效且可扩展的患者健康素养衡量标准(HL )和医生通过采用自然语言处理(NLP)技术和机器学习(ML)的语言复杂性。我们将这些技术应用于超过 400,000 名患者和医生通过电子患者门户交换的安全消息 (SM),开发并验证了自动化的患者素养概况 (LP) 和医生复杂性概况 (CP)。在此,我们描述了这一创新努力中所面临的挑战和实施的解决方案。
材料和方法
为了描述挑战和解决方案,我们使用了两个数据源:研究文件和研究调查人员的访谈。在该项目的五年中,该团队结合使用 Google 文档工具和在线团队组织、跟踪和管理工具 (Asana) 来跟踪他们的研究过程。在第 5 年,团队多次召开会议,对主要挑战和解决方案进行讨论、分类和编码。
结果
我们确定了来自三个总体流程域的 23 项挑战和相关方法:(1) 与 SM 语料库相关的数据挖掘; (2)利用SM语料库上的NLP索引进行分析; (3)跨学科合作。关于数据挖掘,问题包括清理 SM 以进行分析、删除隐藏的护理人员代理(例如其他家庭成员)和西班牙语 SM,以及剔除 SM 以确保仅包括患者的初级保健医生。在分析方面,需要做出关键决策,选择哪些计算语言索引和机器学习方法;如何让基于NLP的语言索引工具顺利运行,并从海量的医学文本语料中提取有意义的数据;以及如何最好地评估 LP 和 CP 的内容和预测有效性。关于跨学科合作,由于研究需要临床医生、卫生服务研究人员、生物医学信息学家、语言学家和认知科学家之间的合作,因此需要不断努力识别和协调科学术语的差异并解决混乱;对需要完成的任务及其优先事项达成共识;在健康服务与认知科学研究中什么代表“有意义的发现”方面达成妥协;并解决有关最终 LP 和 CP 到不同医疗保健环境的潜在可运输性的限制。
讨论
我们的研究代表了对一项创新研究计划的过程评估,该计划旨在利用“大语言数据”来估计患者 HL 和医生的语言复杂性。我们发现的任何挑战如果不加以解决,要么无法生成 LP 和 CP,要么会使与 LP 和 CP 相关的分析结果无效。在 HL 领域进行类似研究或使用计算语言方法来评估患者与临床医生交流的研究人员将面临类似的挑战,并且可能会发现我们的解决方案在设计和执行他们的健康传播研究时很有帮助。










































 京公网安备 11010802027423号
京公网安备 11010802027423号