Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2020-12-05 , DOI: 10.1016/j.jbi.2020.103637 Ethan Steinberg 1 , Ken Jung 1 , Jason A Fries 1 , Conor K Corbin 1 , Stephen R Pfohl 1 , Nigam H Shah 1
|
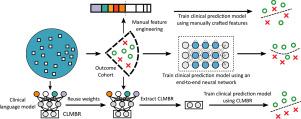
Widespread adoption of electronic health records (EHRs) has fueled the development of using machine learning to build prediction models for various clinical outcomes. However, this process is often constrained by having a relatively small number of patient records for training the model. We demonstrate that using patient representation schemes inspired from techniques in natural language processing can increase the accuracy of clinical prediction models by transferring information learned from the entire patient population to the task of training a specific model, where only a subset of the population is relevant. Such patient representation schemes enable a 3.5% mean improvement in AUROC on five prediction tasks compared to standard baselines, with the average improvement rising to 19% when only a small number of patient records are available for training the clinical prediction model.
中文翻译:
语言模型是一种有效的电子健康记录数据表征学习技术
电子健康记录 (EHR) 的广泛采用推动了使用机器学习为各种临床结果构建预测模型的发展。但是,该过程通常受到用于训练模型的患者记录数量相对较少的限制。我们证明,使用受自然语言处理技术启发的患者表示方案可以通过将从整个患者群体中学到的信息转移到训练特定模型的任务中来提高临床预测模型的准确性,其中只有一部分群体是相关的。与标准基线相比,这种患者表示方案使 AUROC 在五个预测任务上平均提高了 3.5%,


























 京公网安备 11010802027423号
京公网安备 11010802027423号