Chemosphere ( IF 8.8 ) Pub Date : 2020-12-02 , DOI: 10.1016/j.chemosphere.2020.129140 Zhiyuan Li , Xinning Tong , Jason Man Wai Ho , Timothy C.Y. Kwok , Guanghui Dong , Kin-Fai Ho , Steve Hung Lam Yim
|
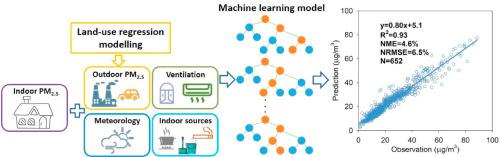
People typically spend most of their time indoors. It is of importance to establish prediction models to estimate PM2.5 concentration in indoor environments (e.g., residential households) to allow accurate assessments of exposure in epidemiological studies. This study aimed to develop models to predict PM2.5 concentration in residential households. PM2.5 concentration and related parameters (e.g., basic information about the households and ventilation settings) were collected in 116 households during the winter and summer seasons in Hong Kong. Outdoor PM2.5 concentration at households was estimated using a land-use regression model. The random forest machine learning algorithm was then applied to develop indoor PM2.5 prediction models. The results show that the random forest model achieved a promising predictive accuracy, with R2 and cross-validation R2 values of 0.93 and 0.65, respectively. Outdoor PM2.5 concentration was the most important predictor variable, followed in descending order by the household marked number, outdoor temperature, outdoor relative humidity, average household area and air conditioning. The external validation result using an independent dataset confirmed the potential application of the random forest model, with an R2 value of 0.47. Overall, this study shows the value of a combined land-use regression and machine learning approach in establishing indoor PM2.5 prediction models that provide a relatively accurate assessment of exposure for use in epidemiological studies.


























 京公网安备 11010802027423号
京公网安备 11010802027423号