Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-11-17 , DOI: 10.1016/j.jbi.2020.103588 Neville Kenneth Kitson 1 , Anthony C Constantinou 2
|
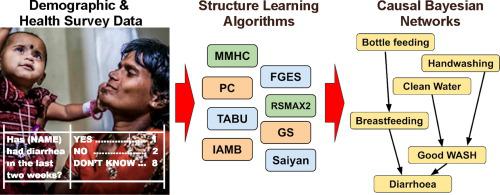
Child mortality from preventable diseases such as pneumonia and diarrhoea in low and middle-income countries remains a serious global challenge. We combine knowledge with available Demographic and Health Survey (DHS) data from India, to construct Causal Bayesian Networks (CBNs) and investigate the factors associated with childhood diarrhoea. We make use of freeware tools to learn the graphical structure of the DHS data with score-based, constraint-based, and hybrid structure learning algorithms. We investigate the effect of missing values, sample size, and knowledge-based constraints on each of the structure learning algorithms and assess their accuracy with multiple scoring functions. Weaknesses in the survey methodology and data available, as well as the variability in the CBNs generated by the different algorithms, mean that it is not possible to learn a definitive CBN from data. However, knowledge-based constraints are found to be useful in reducing the variation in the graphs produced by the different algorithms, and produce graphs which are more reflective of the likely influential relationships in the data. Furthermore, valuable insights are gained into the performance and characteristics of the structure learning algorithms. Two score-based algorithms in particular, TABU and FGES, demonstrate many desirable qualities; a) with sufficient data, they produce a graph which is similar to the reference graph, b) they are relatively insensitive to missing values, and c) behave well with knowledge-based constraints. The results provide a basis for further investigation of the DHS data and for a deeper understanding of the behaviour of the structure learning algorithms when applied to real-world settings.
中文翻译:
从人口统计和健康调查数据中学习贝叶斯网络
低收入和中等收入国家因可预防的疾病(如肺炎和腹泻)导致的儿童死亡率仍然是一个严峻的全球挑战。我们将知识与印度的可用人口统计和健康调查(DHS)数据相结合,以构建因果贝叶斯网络(CBNs),并调查与儿童腹泻相关的因素。我们使用免费软件工具通过基于分数,基于约束和混合结构的学习算法来学习DHS数据的图形结构。我们调查缺失值,样本大小和基于知识的约束条件对每种结构学习算法的影响,并使用多种评分功能评估其准确性。调查方法和可用数据的弱点,以及由不同算法生成的CBN的可变性,这意味着不可能从数据中学习确定的CBN。但是,发现基于知识的约束对于减少由不同算法生成的图形的变化是有用的,并且生成的图形更能反映数据中可能的影响关系。此外,获得了有关结构学习算法的性能和特性的宝贵见解。尤其是两种基于分数的算法TABU和FGES表现出许多理想的质量。a)有足够的数据,它们产生的图形类似于参考图形,b)对缺失值相对不敏感,并且c)在基于知识的约束下表现良好。










































 京公网安备 11010802027423号
京公网安备 11010802027423号