当前位置:
X-MOL 学术
›
Comput. Graph.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Learning to dance: A graph convolutional adversarial network to generate realistic dance motions from audio
Computers & Graphics ( IF 2.5 ) Pub Date : 2021-02-01 , DOI: 10.1016/j.cag.2020.09.009 João P. Ferreira , Thiago M. Coutinho , Thiago L. Gomes , José F. Neto , Rafael Azevedo , Renato Martins , Erickson R. Nascimento
Computers & Graphics ( IF 2.5 ) Pub Date : 2021-02-01 , DOI: 10.1016/j.cag.2020.09.009 João P. Ferreira , Thiago M. Coutinho , Thiago L. Gomes , José F. Neto , Rafael Azevedo , Renato Martins , Erickson R. Nascimento
|
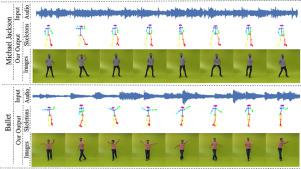
Abstract Synthesizing human motion through learning techniques is becoming an increasingly popular approach to alleviating the requirement of new data capture to produce animations. Learning to move naturally from music, i.e., to dance, is one of the more complex motions humans often perform effortlessly. Each dance movement is unique, yet such movements maintain the core characteristics of the dance style. Most approaches addressing this problem with classical convolutional and recursive neural models undergo training and variability issues due to the non-Euclidean geometry of the motion manifold structure. In this paper, we design a novel method based on graph convolutional networks to tackle the problem of automatic dance generation from audio information. Our method uses an adversarial learning scheme conditioned on the input music audios to create natural motions preserving the key movements of different music styles. We evaluate our method with three quantitative metrics of generative methods and a user study. The results suggest that the proposed GCN model outperforms the state-of-the-art dance generation method conditioned on music in different experiments. Moreover, our graph-convolutional approach is simpler, easier to be trained, and capable of generating more realistic motion styles regarding qualitative and different quantitative metrics. It also presented a visual movement perceptual quality comparable to real motion data. The dataset and project are publicly available at: https://www.verlab.dcc.ufmg.br/motion-analysis/cag2020 .
中文翻译:

学习跳舞:图卷积对抗网络从音频生成逼真的舞蹈动作
摘要 通过学习技术合成人体运动正成为一种越来越流行的方法,以减轻新数据捕获以产生动画的需求。学习从音乐中自然地移动,即跳舞,是人类经常毫不费力地执行的更复杂的动作之一。每个舞蹈动作都是独一无二的,但这些动作都保持了舞蹈风格的核心特征。由于运动流形结构的非欧几何,大多数使用经典卷积和递归神经模型解决这个问题的方法都会经历训练和可变性问题。在本文中,我们设计了一种基于图卷积网络的新方法来解决从音频信息自动生成舞蹈的问题。我们的方法使用以输入音乐音频为条件的对抗性学习方案来创建自然运动,保留不同音乐风格的关键运动。我们使用生成方法的三个定量指标和用户研究来评估我们的方法。结果表明,所提出的 GCN 模型在不同的实验中优于以音乐为条件的最先进的舞蹈生成方法。此外,我们的图卷积方法更简单,更容易训练,并且能够生成关于定性和不同定量指标的更逼真的运动风格。它还呈现了与真实运动数据相当的视觉运动感知质量。数据集和项目可在以下网址公开获取:https://www.verlab.dcc.ufmg.br/motion-analysis/cag2020。
更新日期:2021-02-01
中文翻译:
学习跳舞:图卷积对抗网络从音频生成逼真的舞蹈动作
摘要 通过学习技术合成人体运动正成为一种越来越流行的方法,以减轻新数据捕获以产生动画的需求。学习从音乐中自然地移动,即跳舞,是人类经常毫不费力地执行的更复杂的动作之一。每个舞蹈动作都是独一无二的,但这些动作都保持了舞蹈风格的核心特征。由于运动流形结构的非欧几何,大多数使用经典卷积和递归神经模型解决这个问题的方法都会经历训练和可变性问题。在本文中,我们设计了一种基于图卷积网络的新方法来解决从音频信息自动生成舞蹈的问题。我们的方法使用以输入音乐音频为条件的对抗性学习方案来创建自然运动,保留不同音乐风格的关键运动。我们使用生成方法的三个定量指标和用户研究来评估我们的方法。结果表明,所提出的 GCN 模型在不同的实验中优于以音乐为条件的最先进的舞蹈生成方法。此外,我们的图卷积方法更简单,更容易训练,并且能够生成关于定性和不同定量指标的更逼真的运动风格。它还呈现了与真实运动数据相当的视觉运动感知质量。数据集和项目可在以下网址公开获取:https://www.verlab.dcc.ufmg.br/motion-analysis/cag2020。










































 京公网安备 11010802027423号
京公网安备 11010802027423号