当前位置:
X-MOL 学术
›
Ann. N. Y. Acad. Sci.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
An evolutionary account of intermodality differences in statistical learning
Annals of the New York Academy of Sciences ( IF 4.1 ) Pub Date : 2020-10-05 , DOI: 10.1111/nyas.14502 Mikhail Ordin 1, 2 , Leona Polyanskaya 1 , Arthur G. Samuel 1, 2, 3
Annals of the New York Academy of Sciences ( IF 4.1 ) Pub Date : 2020-10-05 , DOI: 10.1111/nyas.14502 Mikhail Ordin 1, 2 , Leona Polyanskaya 1 , Arthur G. Samuel 1, 2, 3
Affiliation
|
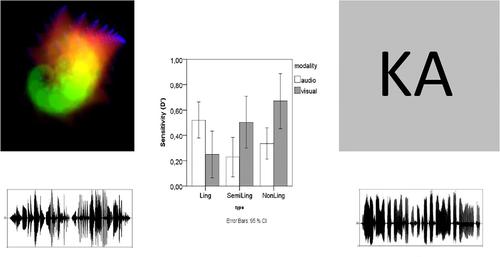
The cognitive mechanisms underlying statistical learning are engaged for the purposes of speech processing and language acquisition. However, these mechanisms are shared by a wide variety of species that do not possess the language faculty. Moreover, statistical learning operates across domains, including nonlinguistic material. Ancient mechanisms for segmenting continuous sensory input into discrete constituents have evolved for general-purpose segmentation of the environment and been readopted for processing linguistic input. Linguistic input provides a rich set of cues for the boundaries between sequential constituents. Such input engages a wider variety of more specialized mechanisms operating on these language-specific cues, thus potentially reducing the role of conditional statistics in tokenizing a continuous linguistic stream. We provide an explicit within-subject comparison of the utility of statistical learning in language versus nonlanguage domains across the visual and auditory modalities. The results showed that in the auditory modality statistical learning is more efficient with speech-like input, while in the visual modality efficiency is higher with nonlanguage input. We suggest that the speech faculty has been important for individual fitness for an extended period, leading to the adaptation of statistical learning mechanisms for speech processing. This is not the case in the visual modality, in which linguistic material presents a less ecological type of sensory input.
中文翻译:

统计学习中多模态差异的进化解释
统计学习背后的认知机制用于语音处理和语言习得。然而,这些机制为许多不具备语言能力的物种所共有。此外,统计学习跨领域运作,包括非语言材料。将连续的感官输入分割成离散成分的古老机制已经演变为环境的通用分割,并被重新选择用于处理语言输入。语言输入为连续成分之间的边界提供了丰富的线索。这种输入涉及更广泛、更专业的机制,对这些特定于语言的线索进行操作,从而可能减少条件统计在标记连续语言流中的作用。我们提供了一个明确的学科内比较,比较了统计学习在视觉和听觉模式中的语言与非语言领域的效用。结果表明,在听觉模态中,统计学习对于类似语音的输入更有效,而在视觉模态中,非语言输入的效率更高。我们建议语音能力在很长一段时间内对个人健康很重要,导致统计学习机制适应语音处理。在视觉形式中情况并非如此,其中语言材料呈现的感官输入不太生态。结果表明,在听觉模态中,统计学习对于类似语音的输入更有效,而在视觉模态中,非语言输入的效率更高。我们建议语音能力在很长一段时间内对个人健康很重要,导致统计学习机制适应语音处理。在视觉形式中情况并非如此,其中语言材料呈现的感官输入不太生态。结果表明,在听觉模态中,统计学习对于类似语音的输入更有效,而在视觉模态中,非语言输入的效率更高。我们建议语音能力在很长一段时间内对个人健康很重要,导致统计学习机制适应语音处理。在视觉形式中情况并非如此,其中语言材料呈现的感官输入不太生态。
更新日期:2020-10-05
中文翻译:
统计学习中多模态差异的进化解释
统计学习背后的认知机制用于语音处理和语言习得。然而,这些机制为许多不具备语言能力的物种所共有。此外,统计学习跨领域运作,包括非语言材料。将连续的感官输入分割成离散成分的古老机制已经演变为环境的通用分割,并被重新选择用于处理语言输入。语言输入为连续成分之间的边界提供了丰富的线索。这种输入涉及更广泛、更专业的机制,对这些特定于语言的线索进行操作,从而可能减少条件统计在标记连续语言流中的作用。我们提供了一个明确的学科内比较,比较了统计学习在视觉和听觉模式中的语言与非语言领域的效用。结果表明,在听觉模态中,统计学习对于类似语音的输入更有效,而在视觉模态中,非语言输入的效率更高。我们建议语音能力在很长一段时间内对个人健康很重要,导致统计学习机制适应语音处理。在视觉形式中情况并非如此,其中语言材料呈现的感官输入不太生态。结果表明,在听觉模态中,统计学习对于类似语音的输入更有效,而在视觉模态中,非语言输入的效率更高。我们建议语音能力在很长一段时间内对个人健康很重要,导致统计学习机制适应语音处理。在视觉形式中情况并非如此,其中语言材料呈现的感官输入不太生态。结果表明,在听觉模态中,统计学习对于类似语音的输入更有效,而在视觉模态中,非语言输入的效率更高。我们建议语音能力在很长一段时间内对个人健康很重要,导致统计学习机制适应语音处理。在视觉形式中情况并非如此,其中语言材料呈现的感官输入不太生态。






































 京公网安备 11010802027423号
京公网安备 11010802027423号