当前位置:
X-MOL 学术
›
Comput. Electr. Eng.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Accelerating sparse matrix–matrix multiplication with GPU Tensor Cores
Computers & Electrical Engineering ( IF 4.0 ) Pub Date : 2020-12-01 , DOI: 10.1016/j.compeleceng.2020.106848 Orestis Zachariadis , Nitin Satpute , Juan Gómez-Luna , Joaquín Olivares
Computers & Electrical Engineering ( IF 4.0 ) Pub Date : 2020-12-01 , DOI: 10.1016/j.compeleceng.2020.106848 Orestis Zachariadis , Nitin Satpute , Juan Gómez-Luna , Joaquín Olivares
|
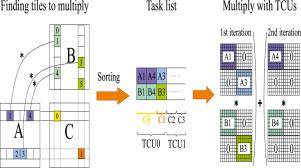
Abstract Sparse general matrix–matrix multiplication (spGEMM) is an essential component in many scientific and data analytics applications. However, the sparsity pattern of the input matrices and the interaction of their patterns make spGEMM challenging. Modern GPUs include Tensor Core Units (TCUs), which specialize in dense matrix multiplication. Our aim is to re-purpose TCUs for sparse matrices. The key idea of our spGEMM algorithm, tSparse, is to multiply sparse rectangular blocks using the mixed precision mode of TCUs. tSparse partitions the input matrices into tiles and operates only on tiles which contain one or more elements. It creates a task list of the tiles, and performs matrix multiplication of these tiles using TCUs. To the best of our knowledge, this is the first time that TCUs are used in the context of spGEMM. We show that spGEMM, with our tiling approach, benefits from TCUs. Our approach significantly improves the performance of spGEMM in comparison to cuSPARSE, CUSP, RMerge2, Nsparse, AC-SpGEMM and spECK.
中文翻译:

使用 GPU Tensor Cores 加速稀疏矩阵 - 矩阵乘法
摘要 稀疏通用矩阵-矩阵乘法 (spGEMM) 是许多科学和数据分析应用程序中的重要组成部分。然而,输入矩阵的稀疏模式及其模式的相互作用使 spGEMM 具有挑战性。现代 GPU 包括张量核心单元 (TCU),专门用于密集矩阵乘法。我们的目标是将 TCU 重新用于稀疏矩阵。我们的 spGEMM 算法 tSparse 的关键思想是使用 TCU 的混合精度模式来乘以稀疏矩形块。tSparse 将输入矩阵划分为瓦片,并且仅对包含一个或多个元素的瓦片进行操作。它创建瓦片的任务列表,并使用 TCU 执行这些瓦片的矩阵乘法。据我们所知,这是第一次在 spGEMM 的上下文中使用 TCU。我们表明 spGEMM,使用我们的平铺方法,可以从 TCU 中受益。与 cuSPARSE、CUSP、RMerge2、Nsparse、AC-SpGEMM 和 spECK 相比,我们的方法显着提高了 spGEMM 的性能。
更新日期:2020-12-01
中文翻译:
使用 GPU Tensor Cores 加速稀疏矩阵 - 矩阵乘法
摘要 稀疏通用矩阵-矩阵乘法 (spGEMM) 是许多科学和数据分析应用程序中的重要组成部分。然而,输入矩阵的稀疏模式及其模式的相互作用使 spGEMM 具有挑战性。现代 GPU 包括张量核心单元 (TCU),专门用于密集矩阵乘法。我们的目标是将 TCU 重新用于稀疏矩阵。我们的 spGEMM 算法 tSparse 的关键思想是使用 TCU 的混合精度模式来乘以稀疏矩形块。tSparse 将输入矩阵划分为瓦片,并且仅对包含一个或多个元素的瓦片进行操作。它创建瓦片的任务列表,并使用 TCU 执行这些瓦片的矩阵乘法。据我们所知,这是第一次在 spGEMM 的上下文中使用 TCU。我们表明 spGEMM,使用我们的平铺方法,可以从 TCU 中受益。与 cuSPARSE、CUSP、RMerge2、Nsparse、AC-SpGEMM 和 spECK 相比,我们的方法显着提高了 spGEMM 的性能。










































 京公网安备 11010802027423号
京公网安备 11010802027423号