Medical & Biological Engineering & Computing ( IF 2.6 ) Pub Date : 2020-09-21 , DOI: 10.1007/s11517-020-02255-0 Ching-Hsing Luo 1, 2 , Haiyi Ye 1 , Xingji Chen 1, 3
|
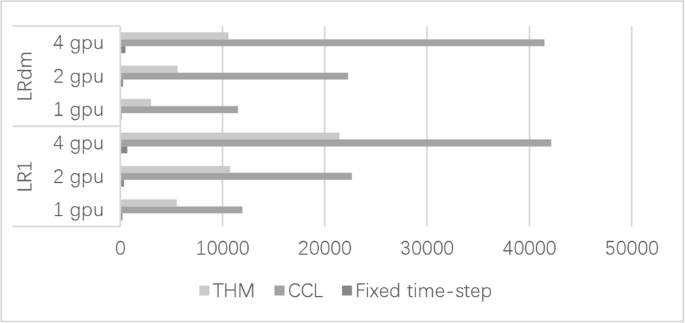
Cardiac electrophysiological simulation is a very complex computational process, which can be run on graphics processing unit (GPU) to save computational cost greatly. The use of adaptive time-step can further effectively speed up the simulation of heart cells. However, if the adaptive time-step method applies to GPU, it suffers synchronization problem on GPU, weakening the acceleration of adaptive time-step method. The previous work ran on a single GPU with the adaptive time-step to get only 1.5 times (× 1.5) faster than the fixed time-step. This study proposes a memory allocation method, which can effectively implement the adaptive time-step method on GPU. The proposed method mainly focuses on the stimulus point and potential memory arrangement in order to achieve optimal memory storage efficiency. All calculation is implemented on GPU. Large matrices such as potential are arranged in column order, and the cells on the left are stimulated. The Luo-Rudy passive (LR1) and dynamic (LRd) ventricular action potential models are used with adaptive time-step methods, such as the traditional hybrid method (THM) and Chen-Chen-Luo’s (CCL) “quadratic adaptive algorithm” method. As LR1 is solved by the THM or CCL on a single GPU, the acceleration is × 34 and × 75 respectively compared with the fixed time-step. With 2 or 4 GPUs, the acceleration of the THM and CCL is × 34 or × 35 and × 73 or × 75, but it would decrease to × 5 or × 3 and × 20 or × 15 without optimization. In an LRd model, the acceleration reaches × 27 or × 85 as solved by the THM or CCL compared with the fixed time-step on multi-GPU with linear speed up increase versus the number of GPU. However, with the increase of GPUs number, the acceleration of the THM and CCL is continuously weakened before optimization. The mixed root mean square error (MRMSE) lower than 5% is applied to ensure the accuracy of simulation. The result shows that the proposed memory arrangement method can save computational cost a lot to speed up the heart simulation greatly.
中文翻译:
基于多GPU的心肌细胞模拟内存优化方法结合自适应时间步长方法[J].
心脏电生理模拟是一个非常复杂的计算过程,可以在图形处理单元(GPU)上运行,大大节省计算成本。采用自适应时间步长可以进一步有效加速心脏细胞的模拟。但是,如果自适应时间步长方法应用于GPU,则在GPU上存在同步问题,削弱了自适应时间步长方法的加速能力。之前的工作在具有自适应时间步长的单个 GPU 上运行,仅比固定时间步长快 1.5 倍(×1.5)。本研究提出了一种内存分配方法,可以有效地在GPU上实现自适应时间步长方法。所提出的方法主要侧重于刺激点和潜在的记忆排列,以实现最佳的记忆存储效率。所有计算均在 GPU 上实现。电位等大矩阵按列顺序排列,左侧的细胞受到刺激。罗-鲁迪被动(LR1)和动态(LRd)心室动作电位模型与自适应时间步长方法一起使用,例如传统的混合方法(THM)和陈-陈-罗(CCL)的“二次自适应算法”方法. 由于 LR1 在单个 GPU 上由 THM 或 CCL 求解,因此与固定时间步长相比,加速度分别为 × 34 和 × 75。使用2或4个GPU时,THM和CCL的加速度为×34或×35和×73或×75,但如果不进行优化,则会降低到×5或×3和×20或×15。在 LRd 模型中,与多 GPU 上的固定时间步长相比,THM 或 CCL 求解的加速度达到 × 27 或 × 85,随着 GPU 数量的线性加速增加。然而,随着GPU数量的增加,THM和CCL的加速在优化前不断减弱。采用低于 5% 的混合均方根误差 (MRMSE) 来保证仿真的准确性。结果表明,所提出的内存排列方法可以大大节省计算成本,大大加快心脏模拟的速度。








































 京公网安备 11010802027423号
京公网安备 11010802027423号