Current Bioinformatics ( IF 2.4 ) Pub Date : 2020-10-31 , DOI: 10.2174/1574893615999200424085947 Yaser Daanial Khan 1 , Ebraheem Alzahrani 2 , Wajdi Alghamdi 3 , Malik Zaka Ullah 2
|
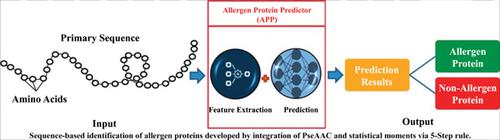
Background: Allergens are antigens that can stimulate an atopic type I human hypersensitivity reaction by an immunoglobulin E (IgE) reaction. Some proteins are naturally allergenic than others. The challenge for toxicologists is to identify properties that allow proteins to cause allergic sensitization and allergic diseases. The identification of allergen proteins is a very critical and pivotal task. The experimental identification of protein functions is a hectic, laborious and costly task; therefore, computer scientists have proposed various methods in the field of computational biology and bioinformatics using various data science approaches. Objectives: Herein, we report a novel predictor for the identification of allergen proteins.
Methods: For feature extraction, statistical moments and various position-based features have been incorporated into Chou’s pseudo amino acid composition (PseAAC), and are used for training of a neural network.
Results: The predictor is validated through 10-fold cross-validation and Jackknife testing, which gave 99.43% and 99.87% accurate results.
Conclusion: Thus, the proposed predictor can help in predicting the Allergen proteins in an efficient and accurate way and can provide baseline data for the discovery of new drugs and biomarkers.
中文翻译:
通过五步法则整合PseAAC和统计矩而开发的基于过敏原蛋白的基于序列的识别
背景:过敏原是可以通过免疫球蛋白E(IgE)反应刺激特应性I型人类过敏反应的抗原。有些蛋白质比其他蛋白质天然具有致敏性。毒理学家面临的挑战是确定允许蛋白质引起过敏性致敏和过敏性疾病的特性。过敏原蛋白的鉴定是非常关键和关键的任务。蛋白质功能的实验鉴定是一项繁重,费力且昂贵的任务。因此,计算机科学家已经使用各种数据科学方法在计算生物学和生物信息学领域提出了各种方法。目标:在这里,我们报告了一种新颖的预测物,用于鉴定过敏原蛋白。
方法:为了提取特征,将统计矩和各种基于位置的特征合并到Chou的伪氨基酸成分(PseAAC)中,并用于训练神经网络。
结果:通过10倍交叉验证和Jackknife测试对预测变量进行了验证,得出了99.43%和99.87%的准确结果。
结论:因此,提出的预测因子可帮助以有效和准确的方式预测过敏原蛋白,并可为发现新药和生物标记物提供基线数据。










































 京公网安备 11010802027423号
京公网安备 11010802027423号