Current Bioinformatics ( IF 2.4 ) Pub Date : 2020-09-30 , DOI: 10.2174/1574893615666200120110205 Yuan Liu 1 , Zhining Wen 1 , Menglong Li 1
|
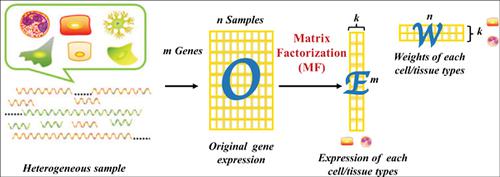
Background: The utilization of genetic data to investigate biological problems has recently become a vital approach. However, it is undeniable that the heterogeneity of original samples at the biological level is usually ignored when utilizing genetic data. Different cell-constitutions of a sample could differentiate the expression profile, and set considerable biases for downstream research. Matrix factorization (MF) which originated as a set of mathematical methods, has contributed massively to deconvoluting genetic profiles in silico, especially at the expression level.
Objective: With the development of artificial intelligence algorithms and machine learning, the number of computational methods for solving heterogeneous problems is also rapidly abundant. However, a structural view from the angle of using MF to deconvolute genetic data is quite limited. This study was conducted to review the usages of MF methods on heterogeneous problems of genetic data on expression level.
Methods: MF methods involved in deconvolution were reviewed according to their individual strengths. The demonstration is presented separately into three sections: application scenarios, method categories and summarization for tools. Specifically, application scenarios defined deconvoluting problem with applying scenarios. Method categories summarized MF algorithms contributed to different scenarios. Summarization for tools listed functions and developed web-servers over the latest decade. Additionally, challenges and opportunities of relative fields are discussed.
Results and Conclusion: Based on the investigation, this study aims to present a relatively global picture to assist researchers to achieve a quicker access of deconvoluting genetic data in silico, further to help researchers in selecting suitable MF methods based on the different scenarios.
中文翻译:
矩阵分解的力量:在表达水平上对遗传异质数据进行反卷积的方法
背景:最近,利用遗传数据调查生物学问题已成为一种至关重要的方法。但是,不可否认的是,在利用遗传数据时,通常会忽略生物学级别的原始样本的异质性。样品的不同细胞组成可能会区分表达谱,并为下游研究设置相当大的偏见。起源于一组数学方法的矩阵分解(MF)已极大地促进了计算机上遗传图谱的去卷积,特别是在表达水平上。
目的:随着人工智能算法和机器学习的发展,解决异构问题的计算方法也迅速丰富。但是,从使用MF解卷积遗传数据的角度来看,结构视图非常有限。这项研究的目的是审查MF方法在表达水平上的遗传数据异质性问题的用法。
方法:根据卷积方法的优点,对卷积方法进行了综述。该演示分为三个部分:应用场景,方法类别和工具概述。具体而言,应用程序场景定义了应用程序场景的解卷积问题。方法类别总结了MF算法对不同场景的贡献。工具的概述列出了最近十年来的功能和已开发的Web服务器。此外,讨论了相关领域的挑战和机遇。
结果与结论:基于调查,本研究旨在提供一个相对全局的图景,以帮助研究人员更快地访问计算机解卷积遗传数据,进一步帮助研究人员根据不同的场景选择合适的MF方法。










































 京公网安备 11010802027423号
京公网安备 11010802027423号