当前位置:
X-MOL 学术
›
Comput. Electron. Agric.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Unsupervised domain adaptation for in-field cotton boll status identification
Computers and Electronics in Agriculture ( IF 7.7 ) Pub Date : 2020-11-01 , DOI: 10.1016/j.compag.2020.105745 Yanan Li , Zhiguo Cao , Hao Lu , Wenxia Xu
Computers and Electronics in Agriculture ( IF 7.7 ) Pub Date : 2020-11-01 , DOI: 10.1016/j.compag.2020.105745 Yanan Li , Zhiguo Cao , Hao Lu , Wenxia Xu
|
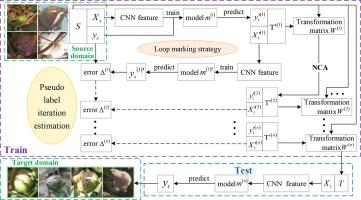
Abstract In-field identification of cotton boll status is an important indicator of maturity grading and precise field management. However, the growth status of cotton boll is highly affected by environmental factors. Differentiation and correlation exhibit in data distribution of different domains, caused by distinct districts, time, weather, and farming operations. Therefore, distribution mismatch is a common phenomenon in agricultural image acquisition such that traditional manual observation measures or standard classification models that are independent and identically distributed (i.i.d.) often cannot obtain satisfactory results. One feasible solution to address this problem is to use domain adaptation that adapts knowledge from the original training data, a.k.a. the source domain, to the new testing data, a.k.a. the target domain. In this paper, we propose a novel NCA-based unsupervised domain adaptation method termed NCADA, which includes three procedures: feature extraction using a deep CNN, feature transformation matrix generation, and target label inference. We validate the NCADA method on our constructed in-field cotton boll dataset with 1 , 600 images. Extensive experiments show that NCADA method achieves accurate identification performances of 86.4 % , 85.3 % and 81.2 % on ‘Internet → Field’ and two different ‘Field → Field’ settings, demonstrating that NCADA can be a useful tool to replace manual observation and standard classification methods.
中文翻译:

用于田间棉铃状态识别的无监督域适应
摘要 棉铃状态的田间鉴定是成熟度分级和田间精准管理的重要指标。然而,棉铃的生长状况受环境因素的影响很大。不同地区、不同时间、不同天气、不同耕作方式导致不同领域的数据分布存在差异性和相关性。因此,分布不匹配是农业图像采集中的普遍现象,传统的人工观测措施或独立同分布(iid)的标准分类模型往往无法获得满意的结果。解决此问题的一种可行解决方案是使用域自适应,将原始训练数据(即源域)中的知识适应新的测试数据(即目标域)。在本文中,我们提出了一种新的基于 NCA 的无监督域适应方法,称为 NCADA,它包括三个过程:使用深度 CNN 进行特征提取、特征变换矩阵生成和目标标签推理。我们使用 1 600 张图像在我们构建的田间棉铃数据集上验证了 NCADA 方法。大量实验表明,NCADA 方法在“Internet → Field”和两种不同的“Field → Field”设置上实现了 86.4 % 、85.3 % 和 81.2 % 的准确识别性能,表明 NCADA 可以成为替代人工观察和标准分类的有用工具方法。我们使用 1 600 张图像在我们构建的田间棉铃数据集上验证了 NCADA 方法。大量实验表明,NCADA 方法在“Internet → Field”和两种不同的“Field → Field”设置上实现了 86.4 % 、85.3 % 和 81.2 % 的准确识别性能,表明 NCADA 可以成为替代人工观察和标准分类的有用工具方法。我们使用 1 600 张图像在我们构建的田间棉铃数据集上验证 NCADA 方法。大量实验表明,NCADA 方法在“Internet → Field”和两种不同的“Field → Field”设置上实现了 86.4 % 、85.3 % 和 81.2 % 的准确识别性能,表明 NCADA 可以成为替代人工观察和标准分类的有用工具方法。
更新日期:2020-11-01
中文翻译:
用于田间棉铃状态识别的无监督域适应
摘要 棉铃状态的田间鉴定是成熟度分级和田间精准管理的重要指标。然而,棉铃的生长状况受环境因素的影响很大。不同地区、不同时间、不同天气、不同耕作方式导致不同领域的数据分布存在差异性和相关性。因此,分布不匹配是农业图像采集中的普遍现象,传统的人工观测措施或独立同分布(iid)的标准分类模型往往无法获得满意的结果。解决此问题的一种可行解决方案是使用域自适应,将原始训练数据(即源域)中的知识适应新的测试数据(即目标域)。在本文中,我们提出了一种新的基于 NCA 的无监督域适应方法,称为 NCADA,它包括三个过程:使用深度 CNN 进行特征提取、特征变换矩阵生成和目标标签推理。我们使用 1 600 张图像在我们构建的田间棉铃数据集上验证了 NCADA 方法。大量实验表明,NCADA 方法在“Internet → Field”和两种不同的“Field → Field”设置上实现了 86.4 % 、85.3 % 和 81.2 % 的准确识别性能,表明 NCADA 可以成为替代人工观察和标准分类的有用工具方法。我们使用 1 600 张图像在我们构建的田间棉铃数据集上验证了 NCADA 方法。大量实验表明,NCADA 方法在“Internet → Field”和两种不同的“Field → Field”设置上实现了 86.4 % 、85.3 % 和 81.2 % 的准确识别性能,表明 NCADA 可以成为替代人工观察和标准分类的有用工具方法。我们使用 1 600 张图像在我们构建的田间棉铃数据集上验证 NCADA 方法。大量实验表明,NCADA 方法在“Internet → Field”和两种不同的“Field → Field”设置上实现了 86.4 % 、85.3 % 和 81.2 % 的准确识别性能,表明 NCADA 可以成为替代人工观察和标准分类的有用工具方法。










































 京公网安备 11010802027423号
京公网安备 11010802027423号